Association Rule Mining¶
Why this matters¶
Association rule mining finds patterns of the form:
The classic example is market basket analysis: customers who buy one product often buy another. But the same idea can apply to playlists, website clicks, medical co-occurrence, or any data where each record is a set of items.
The practical skill is not just running Apriori. The practical skill is interpreting support, confidence, and lift without fooling yourself.
Mental model¶
Imagine each shopping basket as a set:
Association rule mining asks:
Which item combinations appear often enough, and which "if X then Y" rules are stronger than chance?
A rule is directional:
means:
Among transactions containing wine, cheese appears often.
It does not automatically mean wine causes cheese purchases.
Core ideas¶
- A transaction is one basket, session, user profile, or event containing multiple items.
- An itemset is a set of one or more items.
- A frequent itemset appears in enough transactions to pass a support threshold.
- An association rule has an antecedent and a consequent:
antecedent -> consequent. - Support measures how common the itemset is overall.
- Confidence measures how often the consequent appears when the antecedent appears.
- Lift compares the rule against the baseline frequency of the consequent.
- Apriori finds frequent itemsets by growing smaller frequent itemsets into larger candidates.
- FP-growth avoids some Apriori cost by using a compressed frequent-pattern tree.
- Thresholds are modeling choices; different support/confidence/lift values produce different rules.
Walkthrough¶
A tiny night-store example¶
Suppose we have 20 transactions from a small store:
transactions = [
("beer", "wine", "cheese"),
("beer", "potato chips"),
("eggs", "flour", "butter", "cheese"),
("eggs", "flour", "butter", "beer", "potato chips"),
("wine", "cheese"),
("potato chips",),
("eggs", "flour", "butter", "wine", "cheese"),
("eggs", "flour", "butter", "beer", "potato chips"),
("wine", "beer"),
("beer", "potato chips"),
("butter", "eggs"),
("beer", "potato chips"),
("flour", "eggs"),
("beer", "potato chips"),
("eggs", "flour", "butter", "wine", "cheese"),
("beer", "wine", "potato chips", "cheese"),
("wine", "cheese"),
("beer", "potato chips"),
("wine", "cheese"),
("beer", "potato chips"),
]
The visible patterns are already suggestive:
- beer often appears with potato chips
- wine often appears with cheese
- eggs, flour, and butter often appear together
Association rule mining makes those patterns measurable.
Support: how common is the pattern?¶
Support asks:
In what fraction of all transactions does this itemset appear?
If wine and cheese appear together in 7 out of 20 transactions:
High support means the pattern is common. Low support means the pattern may be too rare to care about, even if it looks strong.
Confidence: how reliable is the rule?¶
Confidence asks:
When the antecedent appears, how often does the consequent also appear?
For:
confidence is:
If wine appears in 8 transactions and wine-with-cheese appears in 7:
That says: when wine appears, cheese appears 87.5% of the time.
Lift: is it stronger than the baseline?¶
Confidence alone can mislead. If cheese appears in almost every basket, then wine -> cheese might have high confidence simply because cheese is common.
Lift compares the rule confidence with the baseline support of the consequent:
Interpretation:
- lift near 1: A and B appear together about as often as expected by chance
- lift greater than 1: B is more likely when A appears
- lift less than 1: B is less likely when A appears
Lift is often the most useful first check for whether a rule is interesting.
Why thresholds matter¶
Association rule mining can generate many rules. Thresholds decide what survives.
Common thresholds:
- minimum support: remove rare patterns
- minimum confidence: remove unreliable rules
- minimum lift: remove rules that are not stronger than baseline
- minimum rule length: require at least a certain number of items
Changing thresholds changes the story. A threshold is not just a technical parameter; it is part of the analysis.
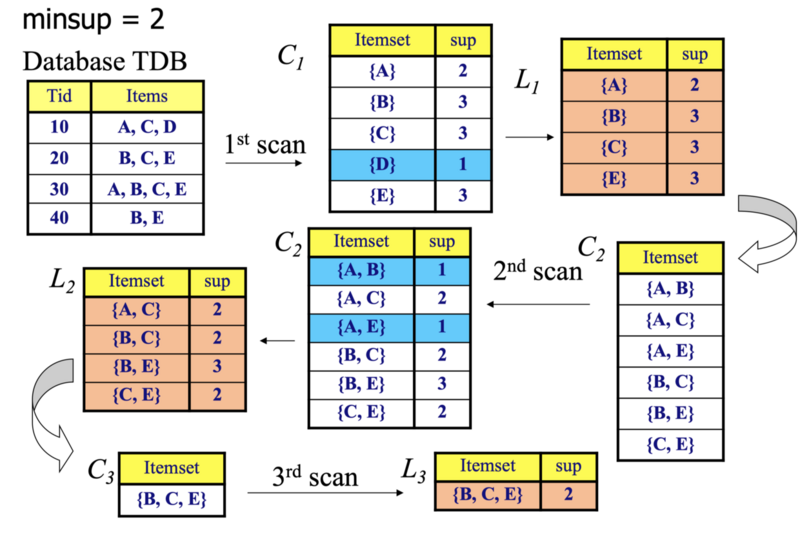
Apriori: grow frequent itemsets¶
Apriori is based on a simple property:
If an itemset is frequent, all of its smaller subsets must also be frequent.
Example:
If {beer, potato chips} is frequent, then {beer} and {potato chips} must each be frequent too.
Apriori uses this to reduce the search space:
- Find frequent single items.
- Combine them into candidate pairs.
- Keep frequent pairs.
- Combine frequent pairs into larger candidates.
- Generate rules from frequent itemsets.
Why Apriori can be expensive¶
Apriori has two main costs:
- it can generate many candidate itemsets
- it repeatedly scans the transaction database to count support
This becomes expensive when there are many items, many transactions, or long baskets.
That is why the notebook introduces FP-growth as an alternative.
FP-growth: compress repeated patterns¶
FP-growth stands for Frequent Pattern Growth.
Instead of generating many candidates like Apriori, FP-growth builds a compressed structure called an FP-tree. The tree stores shared prefixes of transactions, which can reduce repeated scanning.
The study-level distinction:
Apriori: candidate generation and repeated counting
FP-growth: compressed pattern tree and recursive mining
Both are used to find frequent itemsets. FP-growth is often faster for larger or denser transaction data.
From baskets to recommendations¶
The LastFM exercise in the notebook asks how association rules could recommend artists.
Model each user as a transaction:
user 1: Radiohead, The National, Interpol
user 2: Radiohead, Arcade Fire, The National
user 3: Beyoncé, Rihanna, SZA
Then a rule like:
could suggest Interpol to users who listen to Radiohead and The National but not Interpol.
This is not the only recommendation method, but it is an intuitive one.
Explained code examples¶
Run Apriori on transaction tuples¶
from efficient_apriori import apriori
transactions = [
("beer", "wine", "cheese"),
("beer", "potato chips"),
("wine", "cheese"),
("beer", "potato chips"),
]
itemsets, rules = apriori(
transactions,
min_support=0.25,
min_confidence=0.5,
)
for rule in rules:
print(rule)
What this teaches:
- the input is a list of transactions
- each transaction is a tuple or list of items
- support and confidence thresholds filter the output
- the result contains frequent itemsets and generated rules
Convert a basket DataFrame to transactions¶
Many basket datasets are stored as rows where each row contains purchased items and missing values.
transactions = []
for row in store_data.values:
basket = [str(item) for item in row if str(item) != "nan"]
transactions.append(basket)
What this teaches:
- each row becomes one basket
- missing cells are ignored
- algorithms usually expect lists of item names, not a raw rectangular DataFrame
Read rule metrics¶
If a rule prints like:
Read it as:
- support 0.350: wine and cheese appear together in 35% of transactions
- confidence 0.875: when wine appears, cheese appears 87.5% of the time
- lift 2.188: cheese is more than twice as likely when wine appears than in a random basket
That is an actionable rule. A store might place wine and cheese near each other, bundle them, or test a promotion.
Common traps¶
High confidence means the rule is interesting.
Not always. If the consequent is already very common, confidence can be high without the antecedent adding much information. Check lift.
Association means causation.
A rule shows co-occurrence, not that one item causes the other.
Rare but perfect rules are always useful.
A rule with 100% confidence but very low support may be too rare to matter.
Thresholds are objective.
Support, confidence, and lift thresholds are analysis choices. Tune them based on the business question and dataset size.
Apriori output is the final answer.
Rules need interpretation, filtering, and domain judgment. Some rules are obvious, trivial, or operationally useless.
Only retail baskets count.
Any set-like record can work: listened artists per user, visited pages per session, diagnoses per patient, installed apps per device.
FP-growth finds different truths.
FP-growth is mainly a more efficient way to mine frequent patterns. The interpretation of support, confidence, and lift remains the same.
Check yourself¶
What is a transaction in association rule mining?
One record containing a set of items, such as a shopping basket, user listening history, or web session.
What does support measure?
How often an itemset appears across all transactions.
What does confidence measure?
How often the consequent appears among transactions that contain the antecedent.
Why is lift useful?
It compares the rule against the baseline frequency of the consequent, helping reveal whether the association is stronger than chance.
What does a lift near 1 mean?
The antecedent does not change the likelihood of the consequent much compared with baseline.
Why can Apriori be expensive?
It can generate many candidate itemsets and repeatedly scan the transaction database to count support.
What is the core advantage of FP-growth?
It mines frequent patterns using a compressed tree structure, reducing candidate generation and repeated scans.
How could association rules recommend music?
Treat each user's listened artists as a transaction, then recommend consequents from strong rules whose antecedents match the user's current artists.
Source anchors¶
- Source file:
notebooks/Module2/06a-Association Rule Mining.ipynb - Source datasets:
notebooks/Module2/Data/store_data.csv,notebooks/Module2/Data/lastfm.csv - Key source concepts: market basket analysis, frequent itemsets, association rules, support, confidence, lift, Apriori,
apyori,efficient-apriori, FP-growth, LastFM recommendation exercise - Source images:
study-guide/docs/assets/extracted/associationrule.png,study-guide/docs/assets/extracted/exampleapriori.png,study-guide/docs/assets/extracted/aprioridata.jpg