Improving Reasoning with Inference-Time Scaling¶
Why this matters¶
Inference-time scaling improves answers without retraining the model.
Instead of changing weights, we spend more compute while answering:
This lesson implements two practical methods:
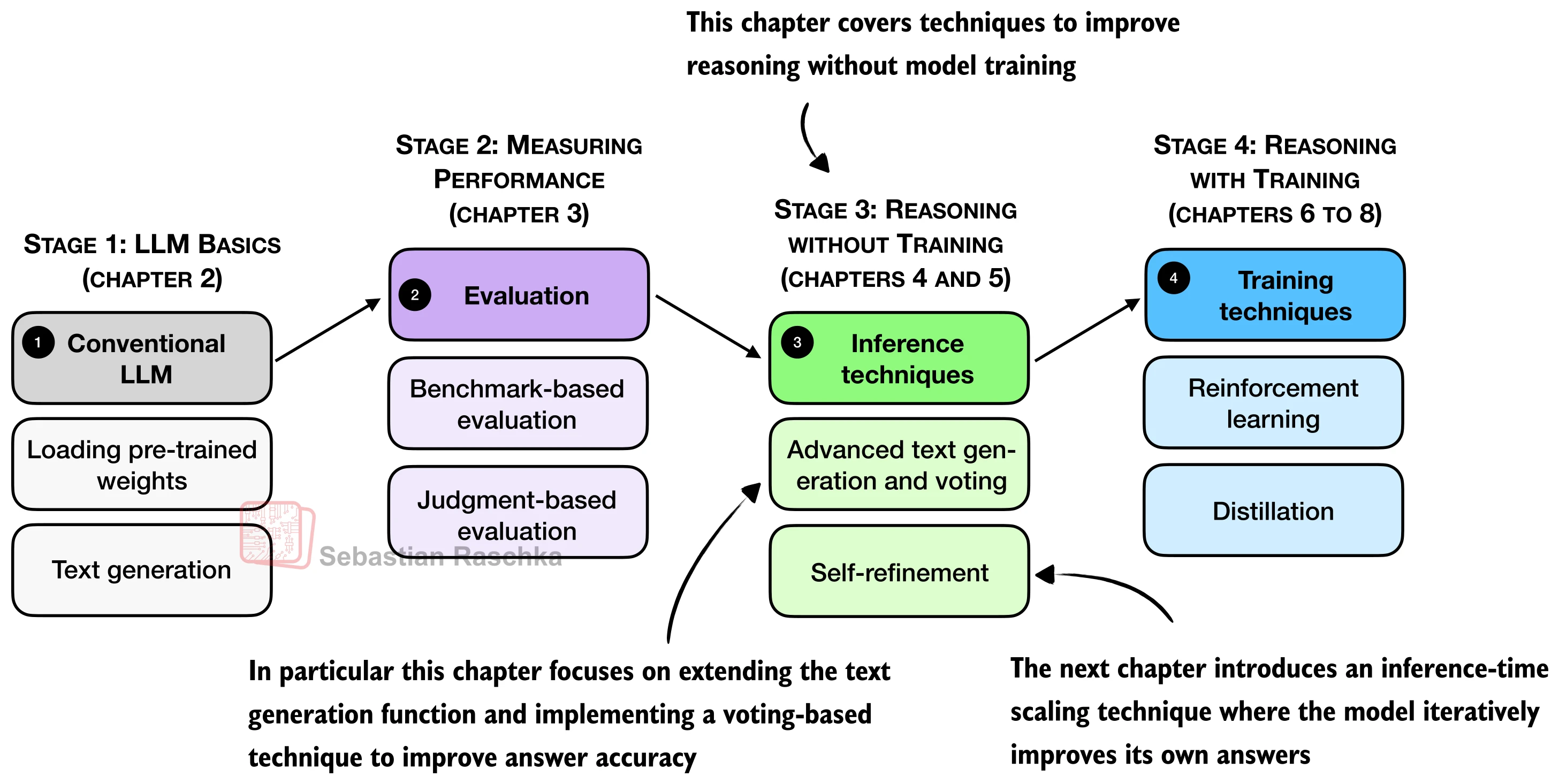
chain-of-thought prompting -> ask for step-by-step reasoning
self-consistency voting -> sample several answers and vote
Mental model¶
Inference-time scaling trades runtime cost for answer quality.
There are several ways to spend more compute:
generate a longer reasoning chain
sample multiple candidate solutions
filter low-quality token choices
vote among extracted final answers
The model weights stay fixed. The extra work happens during generation.
Core ideas¶
- Training-time scaling changes the model through more training compute.
- Inference-time scaling keeps the model fixed and spends more compute at answer time.
- Chain-of-thought prompting can improve reasoning by encouraging intermediate steps.
- Longer reasoning usually means more generated tokens and higher cost.
- Temperature controls how deterministic or diverse sampling is.
- Low temperature makes token choices sharper and more conservative.
- High temperature makes token choices flatter and more diverse.
torch.multinomialsamples tokens according to probability.- Top-p sampling removes very low-probability tokens before sampling.
- Self-consistency generates several solutions and chooses the most frequent final answer.
- Self-consistency depends on answer extraction from the previous verifier lesson.
- In practice, multiple samples can be generated in parallel if hardware allows.
Walkthrough¶
Load the base model¶
The notebook starts with the same Qwen3 base model used in the previous reasoning lessons:
model, tokenizer = load_model_and_tokenizer(
which_model="base",
device=device,
use_compile=False,
)
It tests a MATH-500-style algebra question:
The correct answer is:
The base model initially answers incorrectly. The rest of the notebook tries to improve the result without retraining.
Flexible generation wrapper¶
Earlier lessons used one fixed generation function. This notebook makes the wrapper flexible so different generation methods can be plugged in:
def generate_text_stream_concat_flex(
model,
tokenizer,
prompt,
device,
max_new_tokens,
verbose=False,
generate_func=None,
**generate_kwargs,
):
if generate_func is None:
generate_func = generate_text_basic_stream_cache
input_ids = torch.tensor(
tokenizer.encode(prompt),
device=device,
).unsqueeze(0)
generated_ids = []
for token in generate_func(
model=model,
token_ids=input_ids,
max_new_tokens=max_new_tokens,
eos_token_id=tokenizer.eos_token_id,
**generate_kwargs,
):
next_token_id = token.squeeze(0)
generated_ids.append(next_token_id.item())
if verbose:
print(tokenizer.decode(next_token_id.tolist()), end="", flush=True)
return tokenizer.decode(generated_ids)
The important design choice is:
That lets the notebook reuse the same wrapper for greedy generation, temperature sampling, top-p sampling, and self-consistency.
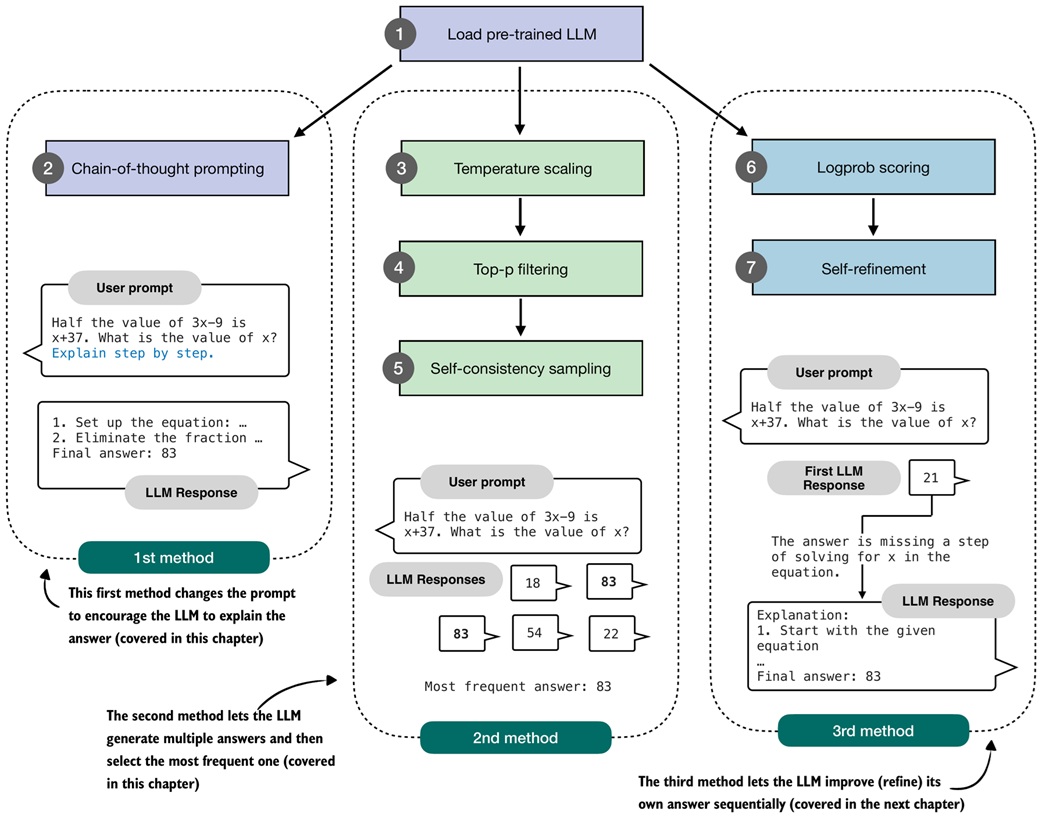
Chain-of-thought prompting¶
Chain-of-thought prompting asks the model to produce intermediate reasoning.
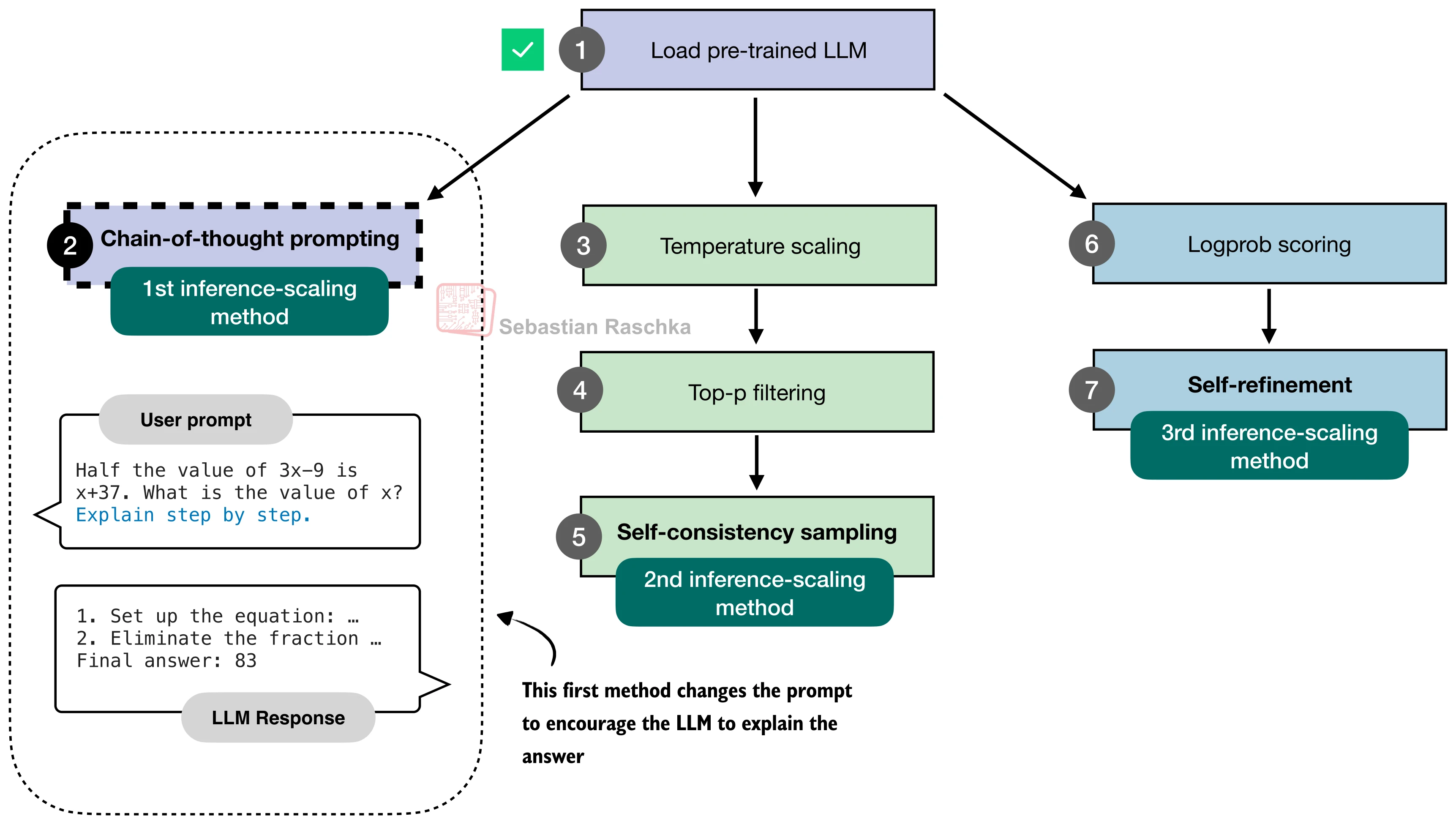
The simplest version appends:
In the notebook's example, this makes the base model produce a longer explanation and reach the correct answer.
Trade-off:
This does not help every model. A model already trained to reason may naturally produce reasoning chains, while a weaker base model may benefit more from the explicit instruction.
Greedy next-token selection¶
Before sampling, the notebook reviews the default next-token process:
Example prompt:
The model produces logits for the next token:
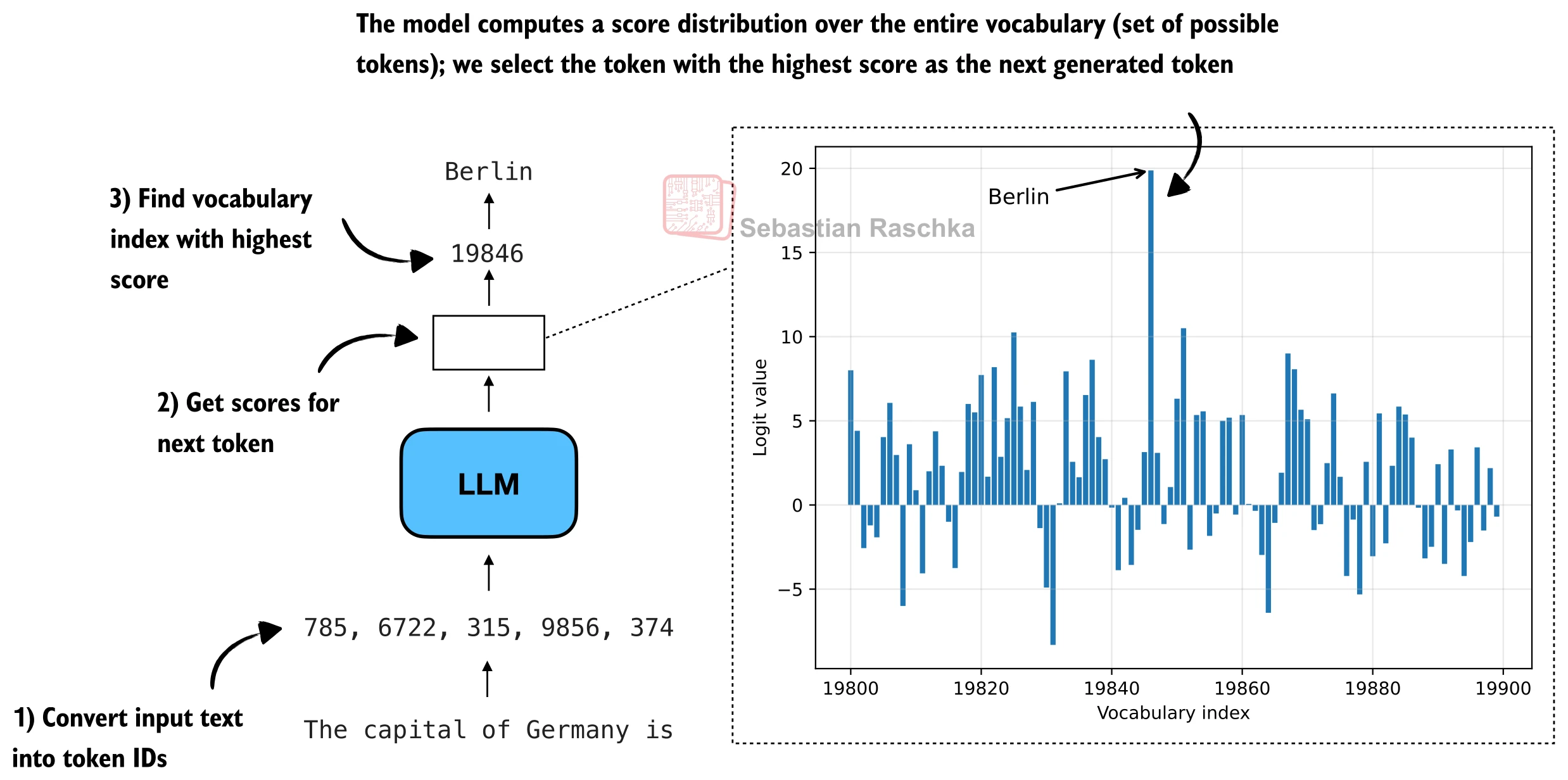
Greedy decoding selects the largest logit:
For this prompt, the high-scoring token should be something like:
Greedy decoding is deterministic. That is useful, but self-consistency needs multiple different candidate answers, so we need sampling.
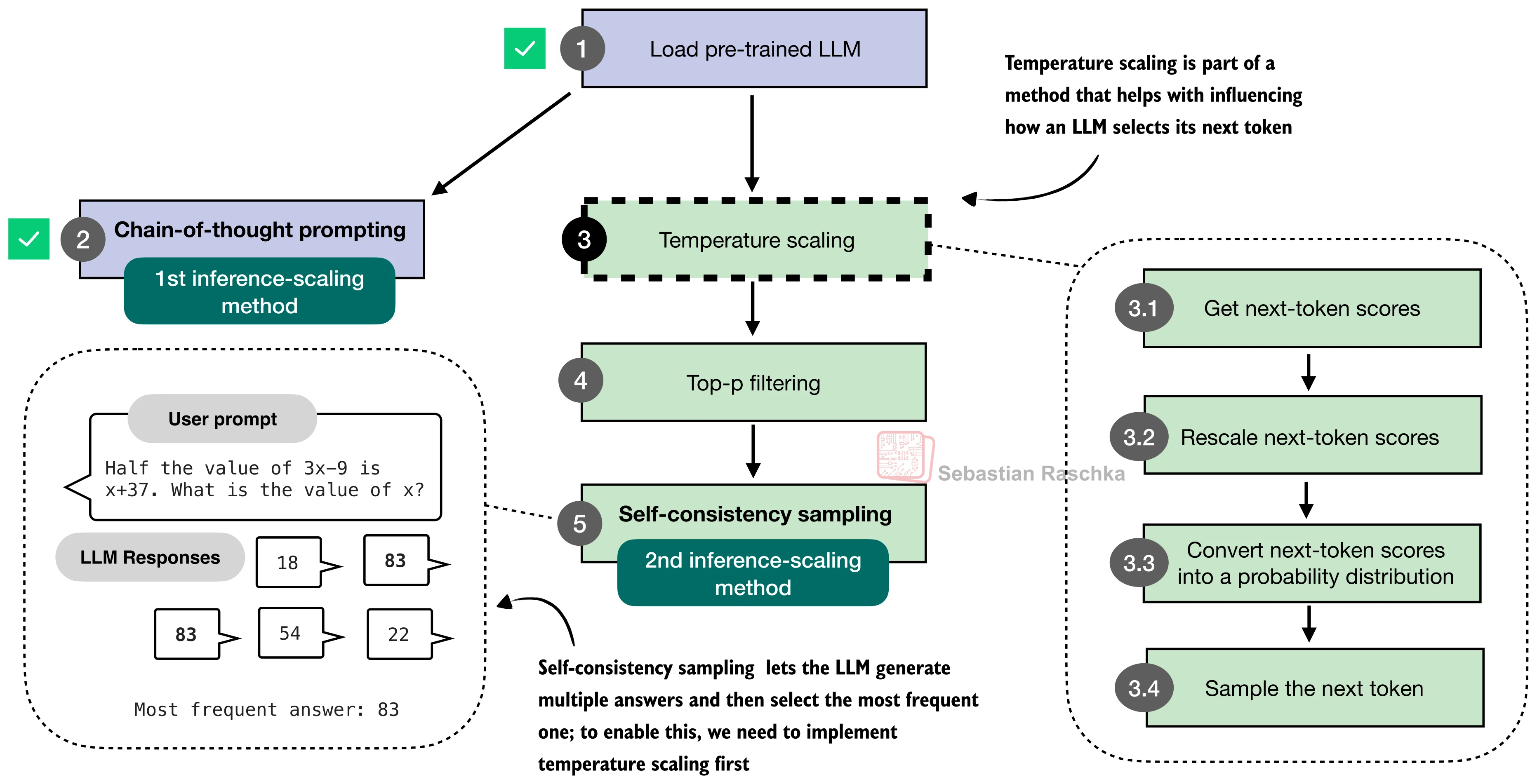
Temperature scaling¶
Temperature changes how sharp or flat token probabilities become.
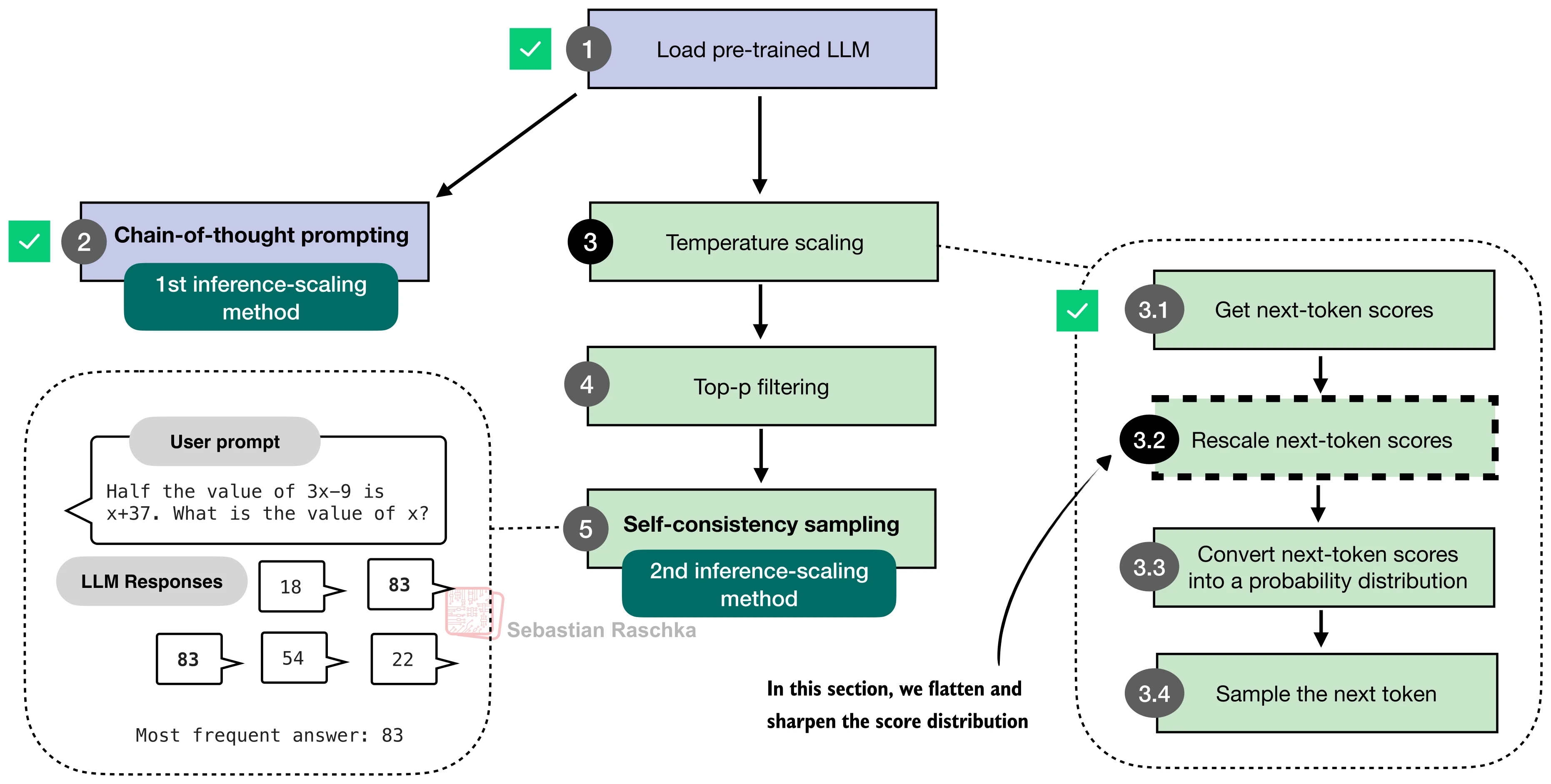
def scale_logits_by_temperature(logits, temperature):
if temperature <= 0:
raise ValueError("Temperature must be positive")
return logits / temperature
Interpretation:
temperature below 1 -> sharper distribution -> more conservative
temperature equal 1 -> unchanged
temperature above 1 -> flatter distribution -> more diverse
After scaling, logits become probabilities with softmax:
logits = scale_logits_by_temperature(next_token_logits, temperature)
probas = torch.softmax(logits, dim=-1)
Then the next token can be sampled:
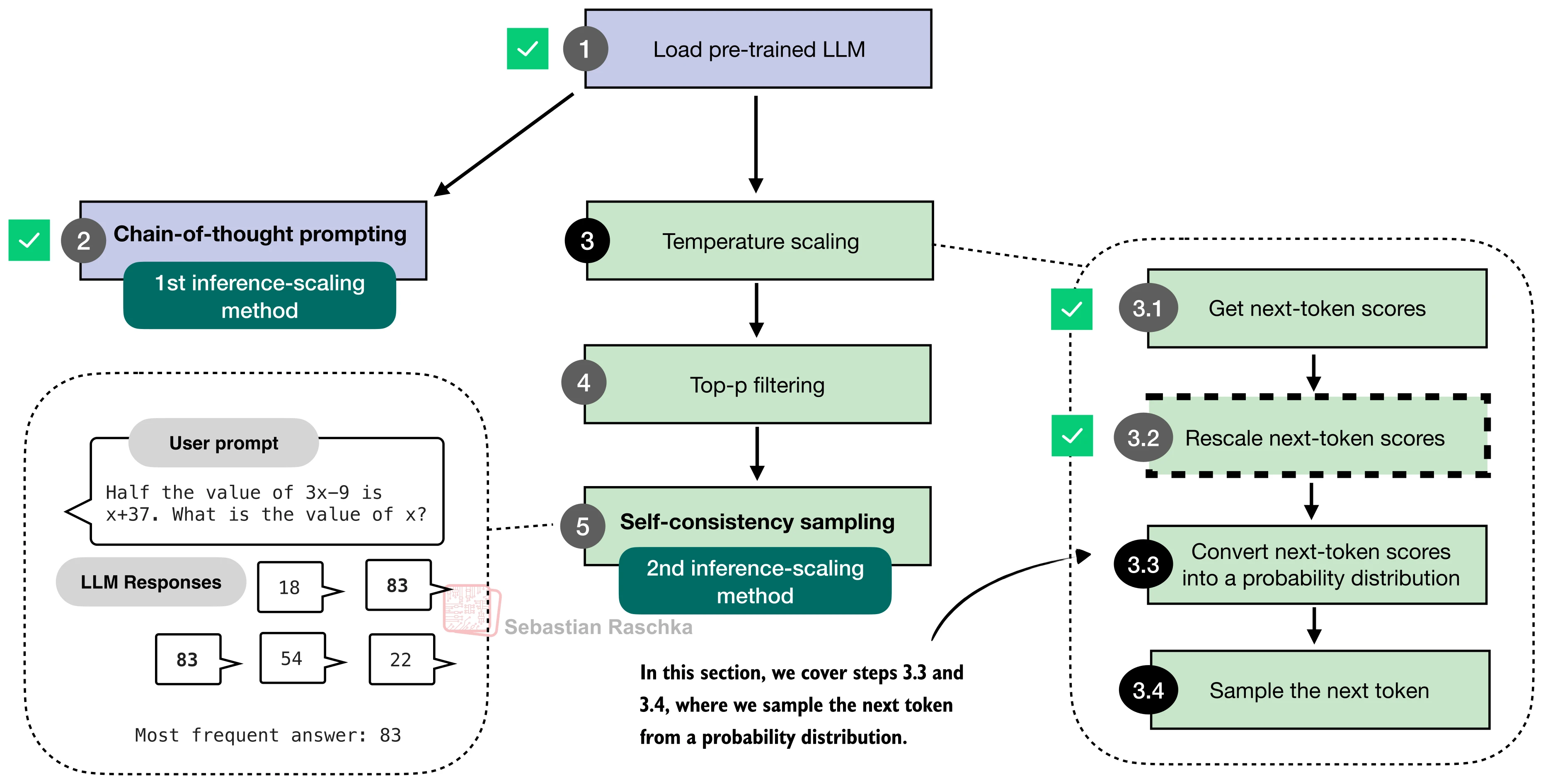
This chooses tokens randomly in proportion to their probabilities. Higher-probability tokens are more likely, but lower-probability tokens can still be selected.
Temperature in generation¶
The notebook adds temperature sampling to generation:
if temperature is None or temperature == 0.0:
next_token = torch.argmax(out, dim=-1, keepdim=True)
else:
logits = scale_logits_by_temperature(out, temperature)
probas = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probas.cpu(), num_samples=1)
The lesson:
Temperature makes it possible to generate different answers for the same prompt. That diversity is needed for voting.
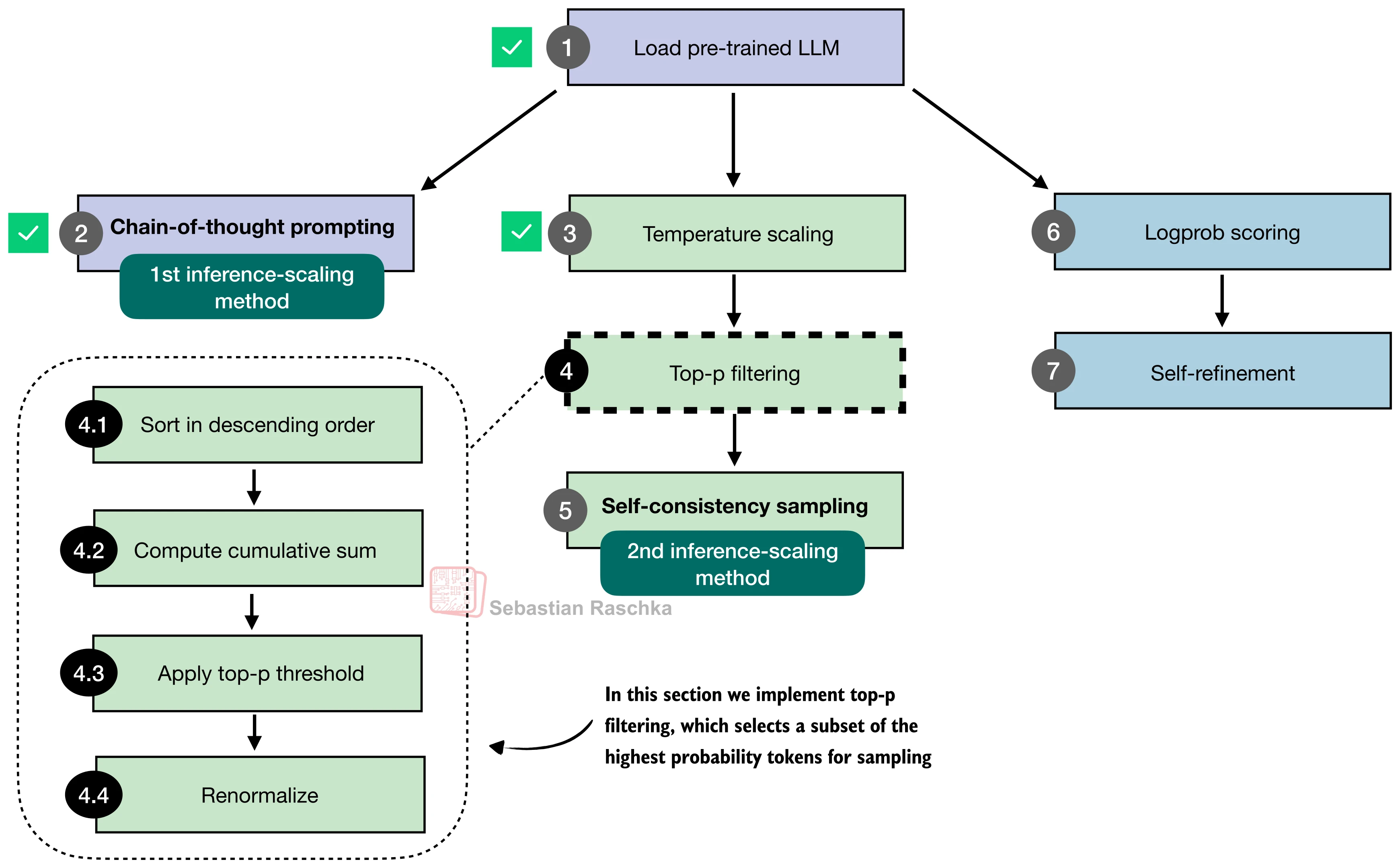
Why top-p sampling is needed¶
Temperature alone can sample odd low-probability tokens, especially if the temperature is too high.
Top-p sampling keeps only the most likely tokens whose cumulative probability mass reaches a threshold.
Example:
token probabilities sorted high to low:
0.45, 0.25, 0.15, 0.05, 0.04, ...
top_p = 0.8
keep enough top tokens to cover about 0.8 probability mass
drop the rest
renormalize kept probabilities
sample from the kept set
This balances:
Top-p filter¶
The notebook implements top-p as:
def top_p_filter(probas, top_p):
if top_p is None or top_p >= 1.0:
return probas
sorted_probas, sorted_idx = torch.sort(probas, dim=1, descending=True)
cumprobas = torch.cumsum(sorted_probas, dim=1)
keep = cumprobas <= top_p
keep[:, 0] = True
kept_sorted = torch.where(
keep,
sorted_probas,
torch.zeros_like(sorted_probas),
)
filtered = torch.zeros_like(probas).scatter(1, sorted_idx, kept_sorted)
denom = torch.sum(filtered, dim=1).clamp_min(1e-12)
return filtered / denom
The four steps:
sort probabilities descending
compute cumulative sum
zero out tokens beyond the cutoff
renormalize remaining probabilities
The line keep[:, 0] = True guarantees that at least the highest-probability token remains.
Temperature plus top-p generation¶
The final generator combines:
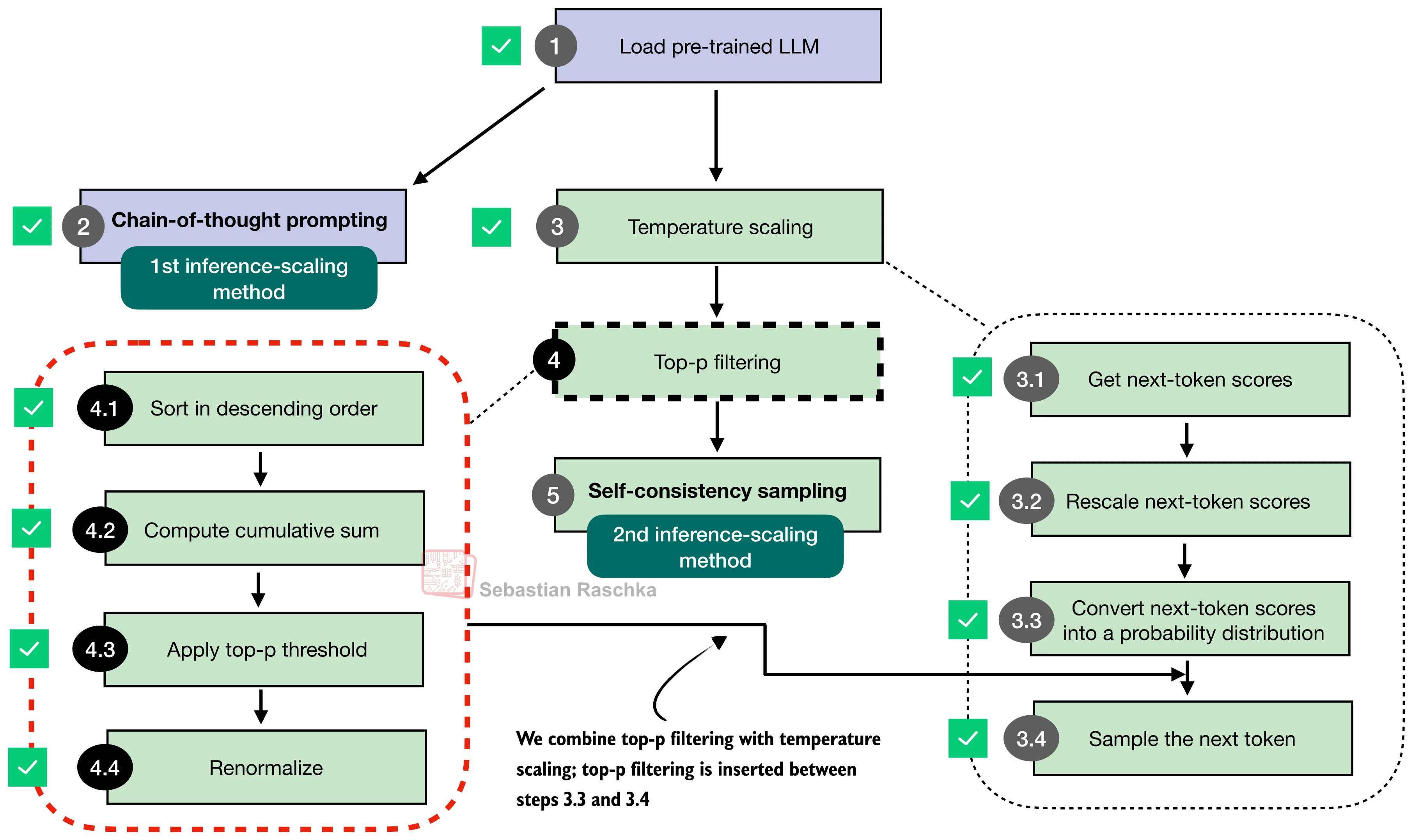
logits = scale_logits_by_temperature(out, temperature)
probas = torch.softmax(logits, dim=-1)
probas = top_p_filter(probas, top_p)
next_token = torch.multinomial(probas.cpu(), num_samples=1)
For the math example, one sampled run can still be wrong. That is expected. The point is not that a single sampled answer is reliable. The point is that sampling gives us several different candidate answers.
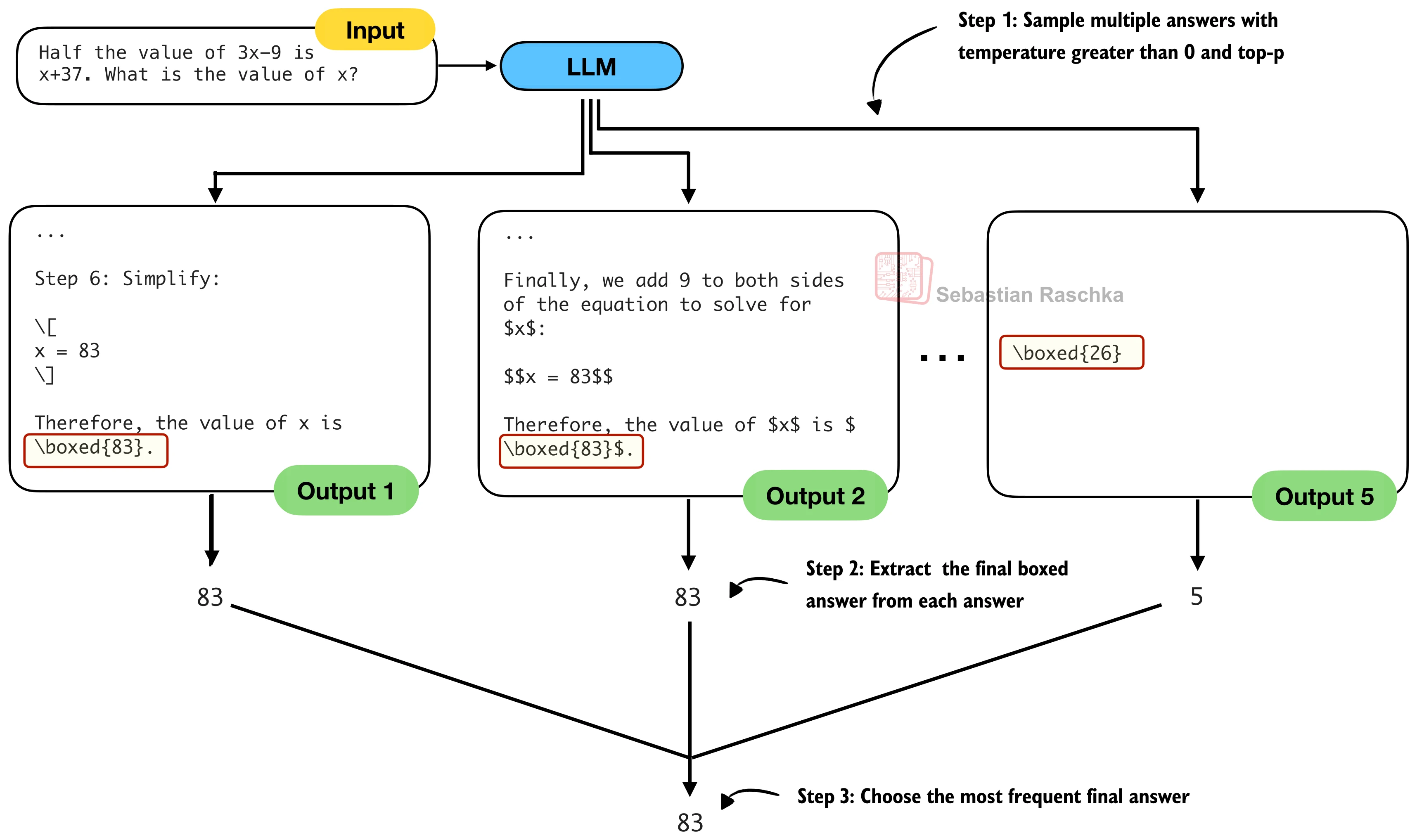
Self-consistency voting¶
Self-consistency is majority voting over sampled reasoning attempts.
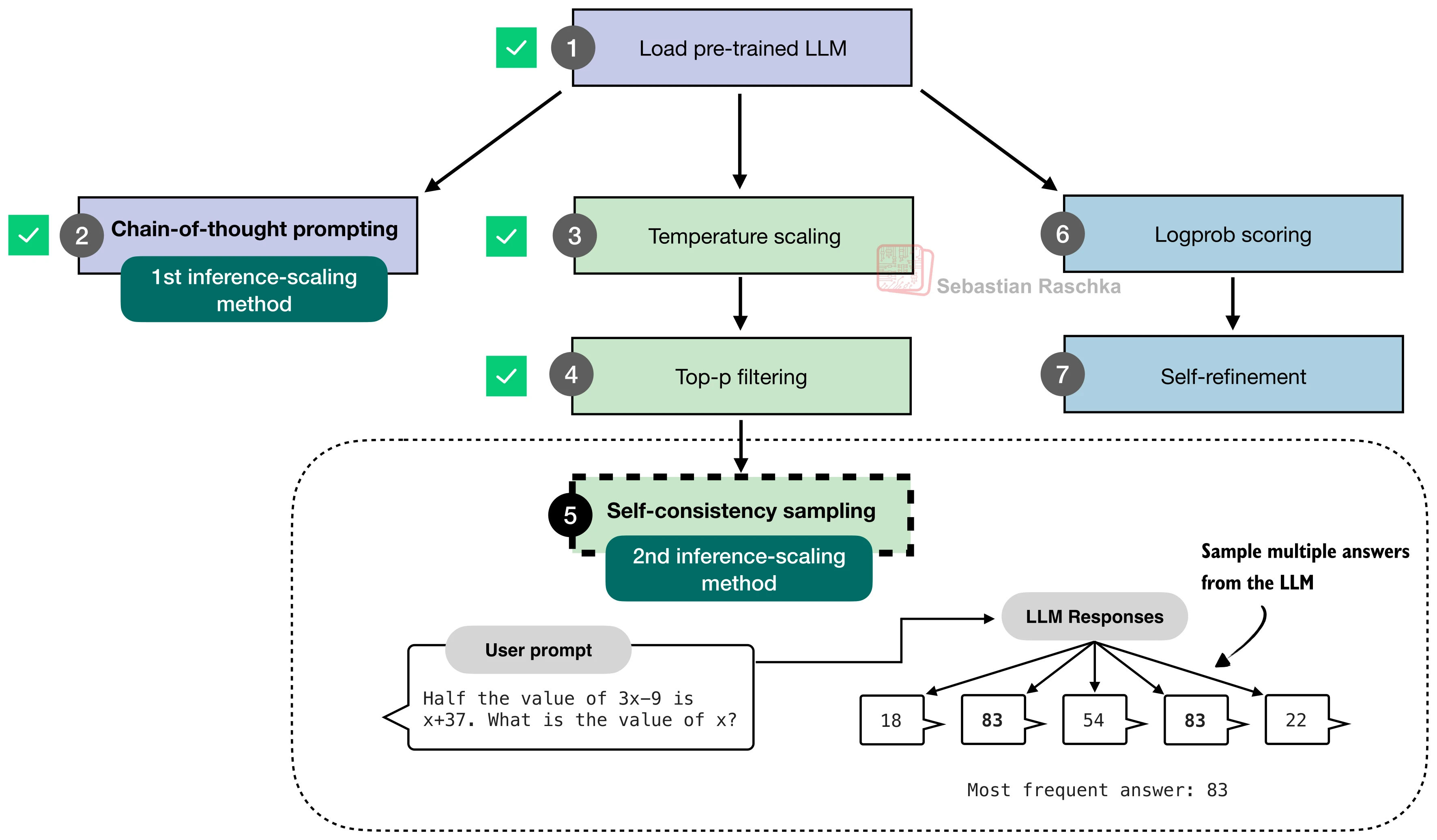
same prompt
sample answer 1 -> extract final answer
sample answer 2 -> extract final answer
sample answer 3 -> extract final answer
sample answer 4 -> extract final answer
sample answer 5 -> extract final answer
choose most frequent final answer
This uses the answer extraction logic from lesson 19b.
The implementation samples multiple responses:
def self_consistency_vote(
model,
tokenizer,
prompt,
device,
num_samples=10,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
seed=None,
):
full_answers, short_answers = [], []
for i in range(num_samples):
if seed is not None:
torch.manual_seed(seed + i + 1)
answer = generate_text_stream_concat_flex(
model=model,
tokenizer=tokenizer,
prompt=prompt,
device=device,
max_new_tokens=max_new_tokens,
generate_func=generate_text_top_p_stream_cache,
temperature=temperature,
top_p=top_p,
)
short = extract_final_candidate(answer, fallback="number_then_full")
full_answers.append(answer)
short_answers.append(short)
counts = Counter(short_answers)
final_answer = counts.most_common(1)[0][0] if counts else None
return {
"final_answer": final_answer,
"short_answers": short_answers,
"full_answers": full_answers,
"counts": counts,
}
In the notebook's algebra example, five sampled answers are enough for the answer 83 to win.
Chain-of-thought plus self-consistency¶
The two methods can be combined:
results = self_consistency_vote(
model,
tokenizer,
prompt + "\n\nExplain step by step.",
device=device,
num_samples=5,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
seed=123,
)
The combined strategy is:
This is a classic inference-time scaling pattern. It can improve accuracy, but it multiplies cost roughly by the number of samples and the length of each answer.
Cost and parallelism¶
If we generate five samples sequentially:
If we generate five samples in parallel:
So self-consistency has two budgets:
quality budget -> how many samples improve accuracy
compute budget -> how much latency and hardware you can afford
Common traps¶
Do not think inference-time scaling changes the model
The weights stay fixed. The improvement comes from prompting, sampling, voting, or refinement during generation.
Do not assume chain-of-thought is always better
Some models already reason by default, and some tasks do not need long reasoning. Extra tokens can add cost without improving accuracy.
Do not set temperature high just to get diversity
Very high temperature can sample incoherent or irrelevant tokens. Diversity is useful only if candidates remain plausible.
Do not use top-p without renormalizing
After filtering tokens, the remaining probabilities no longer sum to one. They must be renormalized before sampling.
Do not treat one sampled answer as the point
Sampling is useful because it creates multiple candidates. Self-consistency relies on the pattern across samples, not one lucky run.
Do not ignore ties in voting
If two answers receive the same count, the system needs a tie-breaker or should report uncertainty.
Do not forget extraction quality
Self-consistency votes over extracted final answers. If extraction is wrong, the vote is wrong too.
Check yourself¶
What is inference-time scaling?
It is spending more compute during answer generation without changing the model weights.
Why can chain-of-thought prompting improve accuracy?
It encourages the model to generate intermediate reasoning steps instead of jumping directly to a final answer.
What does temperature control?
Temperature controls how sharp or flat the token probability distribution is before sampling.
What happens when temperature is too high?
The distribution becomes too flat, so low-quality or irrelevant tokens become more likely.
What does top-p filtering do?
It keeps only the most probable tokens up to a cumulative probability threshold, then renormalizes and samples from that subset.
Why does self-consistency need sampling?
It needs multiple different candidate solutions. Greedy decoding would tend to produce the same answer each time.
How does self-consistency choose the final answer?
It extracts the final answer from each sampled response and chooses the most frequent extracted answer.
What is the main cost of self-consistency?
It requires multiple generations, often with long reasoning chains, so it increases compute, latency, and token usage.
Source anchors¶
notebooks/Module2/19c-Improving Reasoning With Inference-Time Scaling.ipynbstudy-guide/drafts/19c-improving-reasoning-with-inference-time-scaling.md