Spam Classification Finetuning¶
Why this matters¶
Pretraining teaches a model general language patterns. Finetuning adapts that general model to a specific job.
This lesson uses SMS spam detection as the concrete job:
The important shift is that the model is no longer being trained to predict the next word. It is being trained to choose one label from a small fixed set.
Mental model¶
Classification finetuning turns a language model into a specialist.
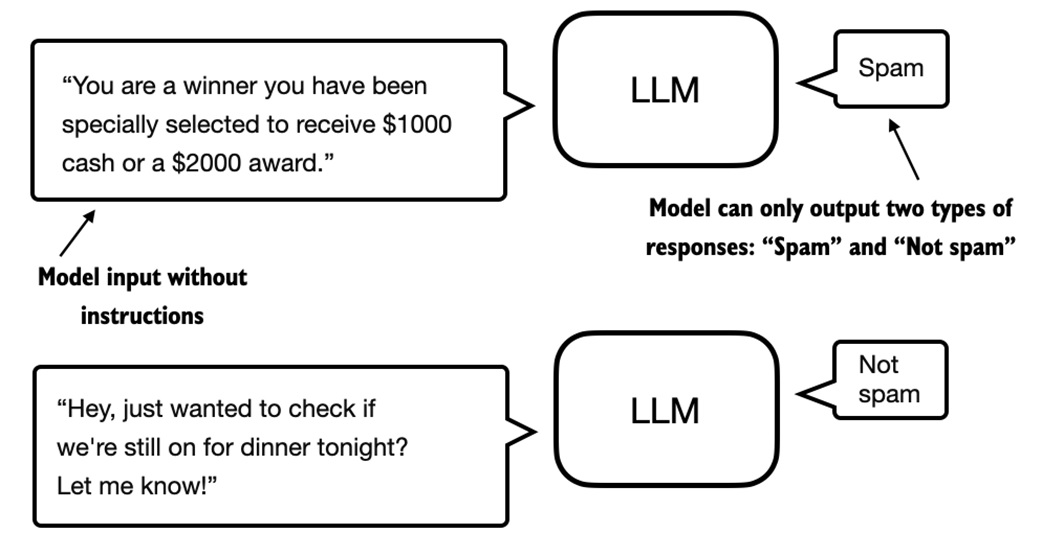
Think of the pretrained GPT model as a strong text reader. For spam classification, we keep most of that reading ability, replace the huge vocabulary output layer with a tiny label output layer, and train the model to map a whole message to one class.
pretrained GPT:
tokens -> hidden states -> 50,257 vocabulary scores
spam classifier:
tokens -> hidden states -> 2 class scores
The two class scores represent:
Core ideas¶
- Instruction finetuning trains a model to follow broad natural-language tasks.
- Classification finetuning trains a model to choose among known labels.
- Spam detection is binary classification: each message is either spam or not spam.
- Class imbalance matters; if most examples are not spam, accuracy can look good while the model ignores spam.
- Messages have different lengths, so batches need padding or truncation.
- The notebook pads with GPT-2's end-of-text token ID,
50256. - The pretrained GPT output head is replaced with a new two-class output head.
- Most parameters are frozen; the output head, final normalization layer, and last transformer block are trained.
- For a causal GPT model, the last token position is used for classification because it can attend to all earlier tokens.
- Cross-entropy loss trains the class logits.
- Accuracy is useful for evaluation, but it is not the loss being optimized.
- Validation data guides tuning; test data should be saved for the final estimate.
Walkthrough¶
Two kinds of finetuning¶
The notebook starts by separating two common finetuning styles.
Instruction finetuning teaches a model to respond to many kinds of requests:
Classification finetuning is narrower:
That narrower scope is a feature. It usually needs less data and compute than broad instruction finetuning, but the model can only predict the labels it was trained on.
Prepare the SMS dataset¶
The dataset contains SMS messages with labels:
The notebook loads the tab-separated file into a DataFrame:
The raw dataset has many more ham messages than spam messages. If we train directly on that imbalance, a lazy model can get many examples right just by predicting ham most of the time.
The notebook balances the data by undersampling ham:
Then it converts text labels to numeric labels:
Finally, it splits the balanced data:
Plain interpretation:
- train set: learn parameters
- validation set: monitor and tune choices
- test set: final held-out performance check
Tokenize and pad messages¶
Earlier language-model pretraining used fixed-length chunks from a long text. Spam messages are different: each SMS is its own example, and messages have different lengths.
A batch cannot directly hold sequences of many different lengths, so we need a policy:
truncate to a common length -> faster, but may discard important words
pad to a common length -> preserves text, but adds extra tokens
The notebook chooses padding.
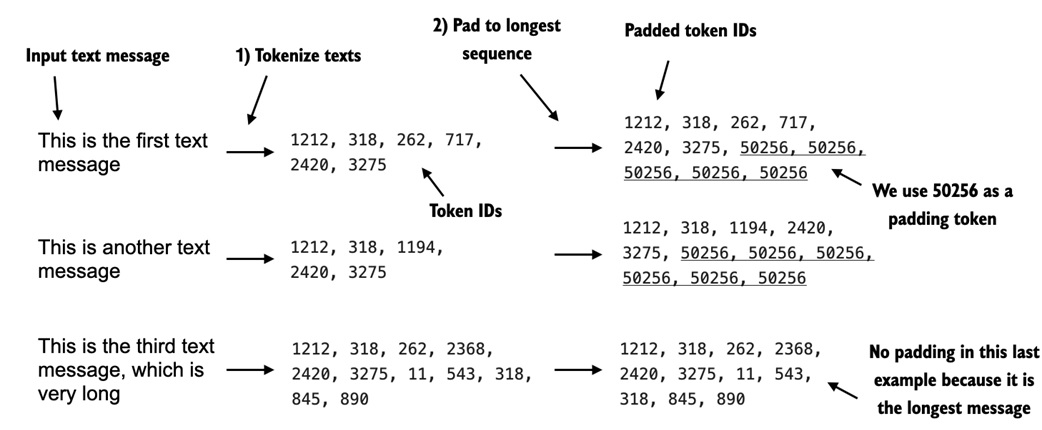
Each message is encoded with the GPT-2 tokenizer. Shorter messages are padded with token ID 50256.
The dataset class does three jobs:
class SpamDataset(Dataset):
def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):
self.data = pd.read_csv(csv_file)
self.encoded_texts = [
tokenizer.encode(text) for text in self.data["Text"]
]
self.max_length = max_length or self._longest_encoded_length()
self.encoded_texts = [
encoded_text[:self.max_length]
for encoded_text in self.encoded_texts
]
self.encoded_texts = [
encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))
for encoded_text in self.encoded_texts
]
The training dataset decides the maximum length. Validation and test use that same length so every split is processed consistently:
train_dataset = SpamDataset("train.csv", tokenizer, max_length=None)
val_dataset = SpamDataset(
"validation.csv",
tokenizer,
max_length=train_dataset.max_length,
)
test_dataset = SpamDataset(
"test.csv",
tokenizer,
max_length=train_dataset.max_length,
)
Create classification batches¶
The DataLoader now returns input tokens and class labels:
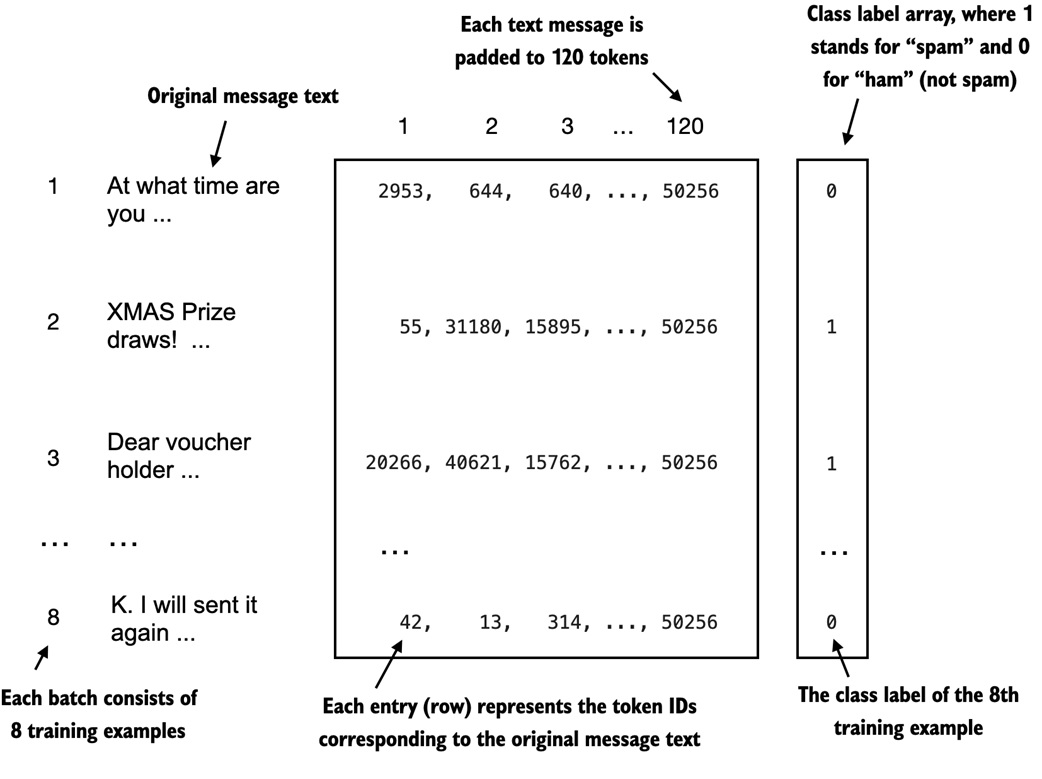
For batch size 8 and message length 120:
This is different from pretraining.
Load the pretrained GPT model¶
The notebook reuses the GPT model architecture and loads GPT-2 weights.
At this point the model can generate text, but it is not yet a good spam classifier. Prompting it with “is this spam?” is unreliable because the model was pretrained, not instruction-finetuned.
That motivates changing the model structure for classification.
Replace the output head¶
The original GPT output head predicts a vocabulary token:
Spam classification only needs two scores:
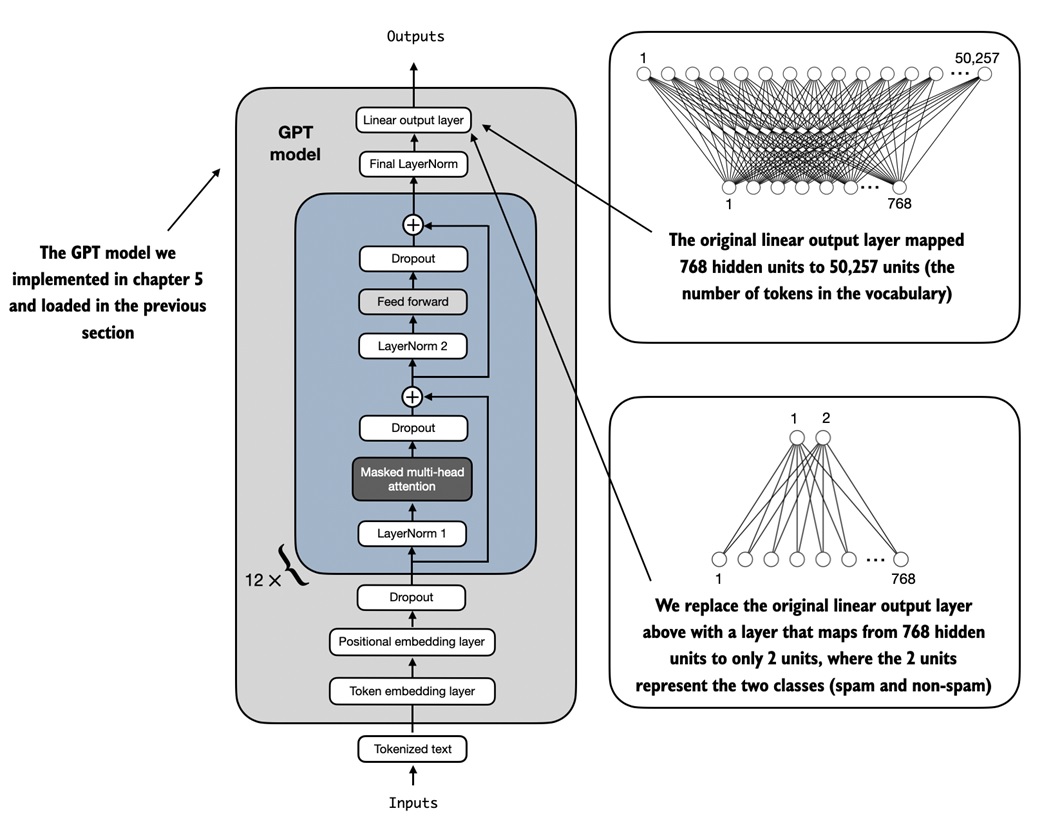
The notebook first freezes every existing parameter:
Then it replaces the output head:
num_classes = 2
model.out_head = torch.nn.Linear(
in_features=BASE_CONFIG["emb_dim"],
out_features=num_classes,
)
The new output head is trainable by default.
The notebook also unfreezes the last transformer block and final layer normalization:
for param in model.trf_blocks[-1].parameters():
param.requires_grad = True
for param in model.final_norm.parameters():
param.requires_grad = True
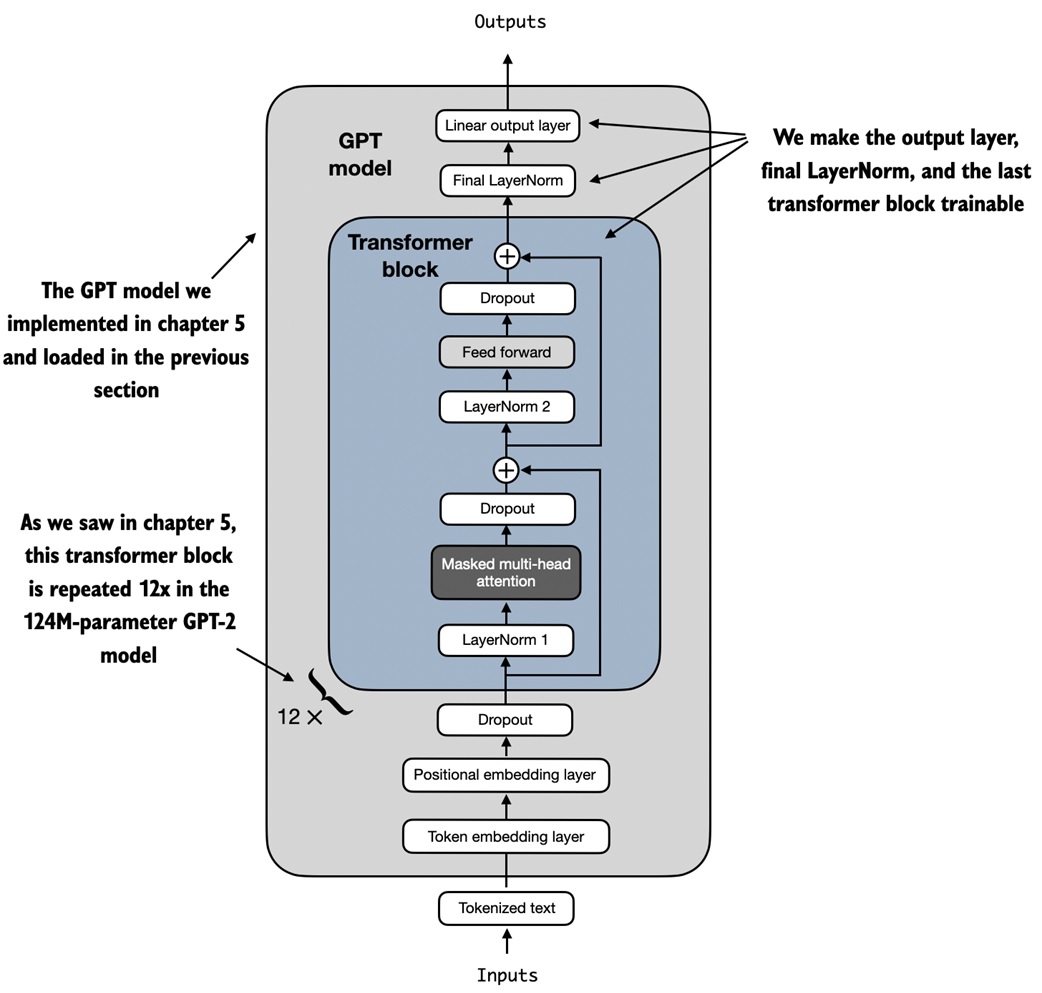
This is a pragmatic compromise:
- keep most pretrained knowledge fixed
- train enough of the model to adapt to the spam task
- reduce compute compared with updating every parameter
Why the last token matters¶
After replacing the head, the model output shape changes.
For one message with 4 tokens:
There are two class scores at every token position.
For classification, the notebook uses only the final position:
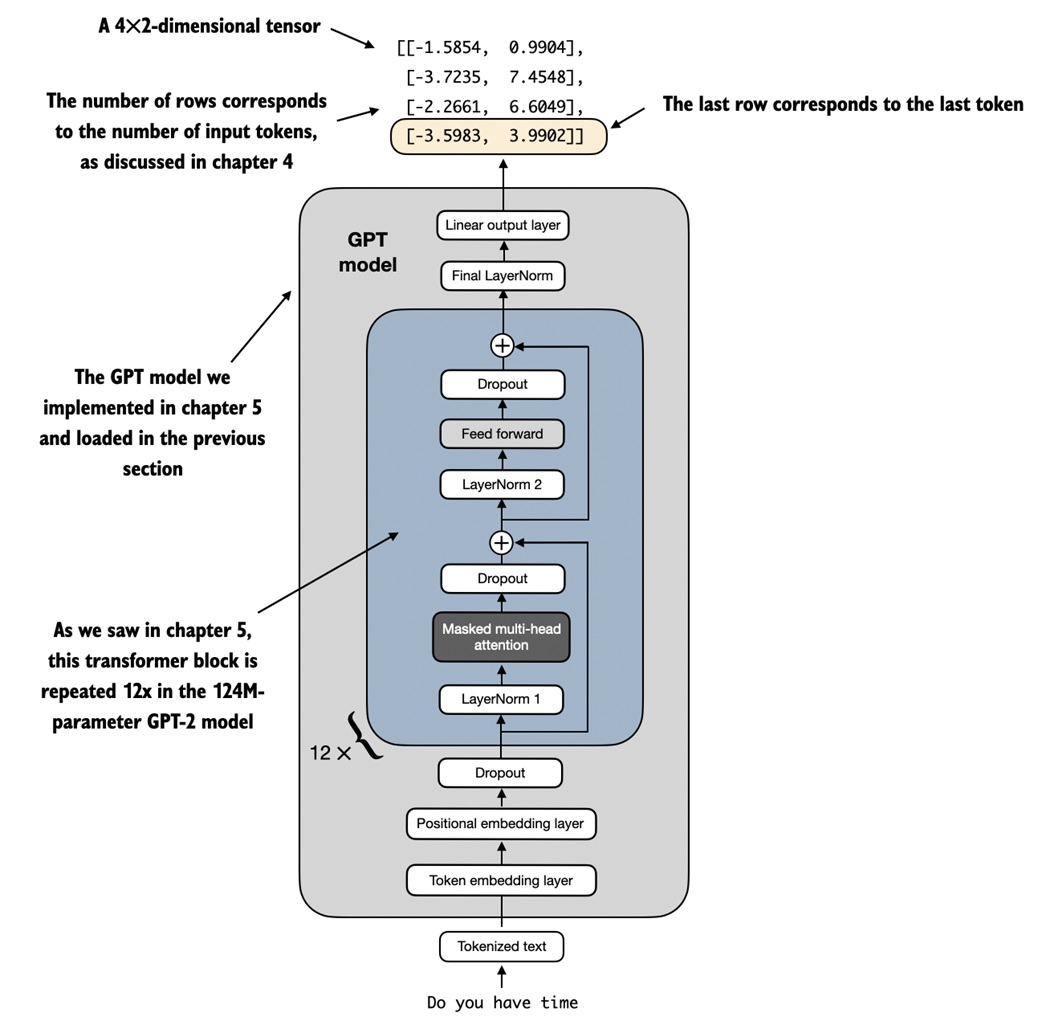
Why the final position?
GPT uses causal attention. Token 1 cannot see future tokens. Token 2 can see token 1 and itself. The last token can see the whole message before it.
So the last token representation is the best single place to summarize the message.
Convert logits to labels¶
The model gives raw class scores, called logits:
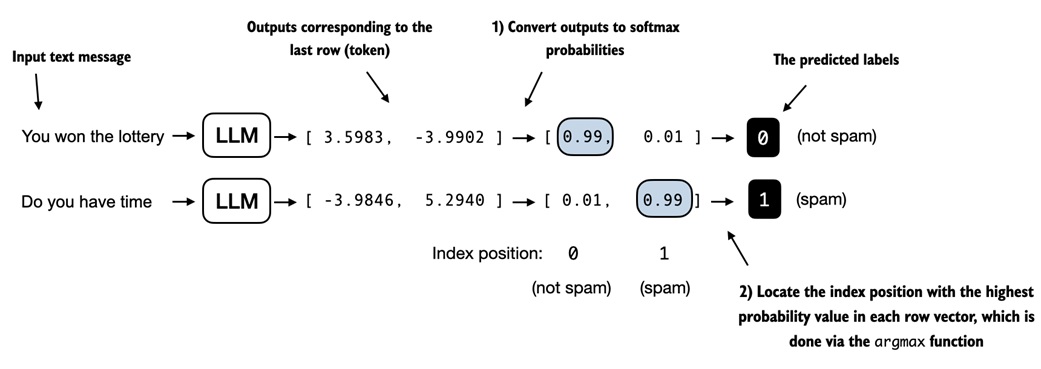
To predict a label, choose the larger score:
You do not need softmax for the prediction. Softmax changes the scores into probabilities, but it does not change which score is largest.
Measure accuracy¶
Accuracy is the fraction of examples where the predicted label matches the target label:
def calc_accuracy_loader(data_loader, model, device, num_batches=None):
model.eval()
correct_predictions, num_examples = 0, 0
for input_batch, target_batch in data_loader:
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
with torch.no_grad():
logits = model(input_batch)[:, -1, :]
predicted_labels = torch.argmax(logits, dim=-1)
num_examples += predicted_labels.shape[0]
correct_predictions += (predicted_labels == target_batch).sum().item()
return correct_predictions / num_examples
Before finetuning, accuracy is near random because the new classification head has not learned the task yet.
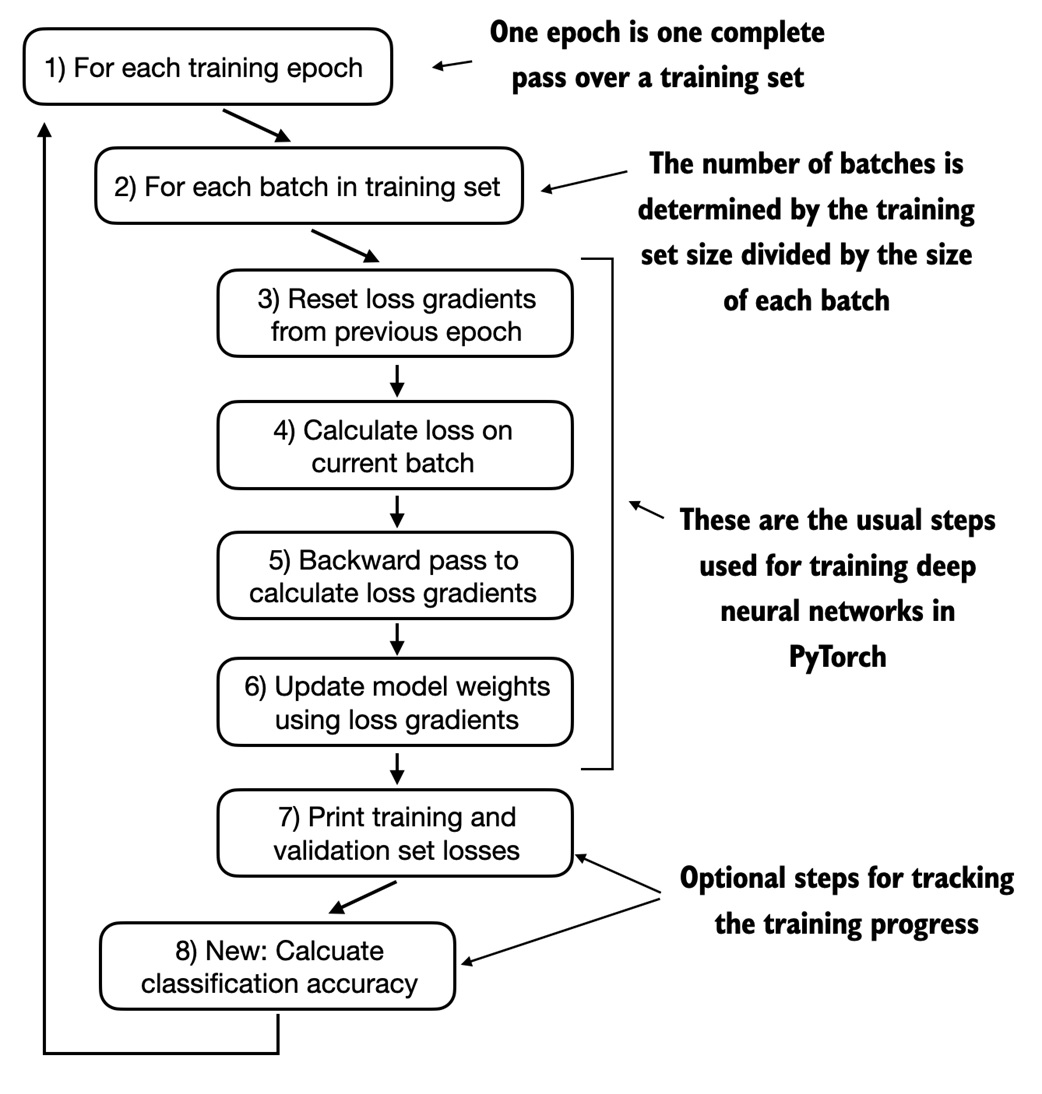
Train with cross-entropy loss¶
Accuracy is good for reporting, but it is not differentiable. Training uses cross-entropy loss:
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)[:, -1, :]
loss = torch.nn.functional.cross_entropy(logits, target_batch)
return loss
The training loop is almost the same as the pretraining loop:
The main difference is what gets evaluated:
The notebook uses AdamW:
After training, both loss and accuracy improve sharply. The full train, validation, and test accuracies are then computed over the complete splits, not just a few batches.
Use the classifier¶
Inference repeats the same preprocessing as the dataset:
def classify_message(text, model, tokenizer, device, max_length, pad_token_id=50256):
model.eval()
input_ids = tokenizer.encode(text)
input_ids = input_ids[:max_length]
input_ids += [pad_token_id] * (max_length - len(input_ids))
input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0)
with torch.no_grad():
logits = model(input_tensor)[:, -1, :]
predicted_label = torch.argmax(logits, dim=-1).item()
return "spam" if predicted_label == 1 else "not spam"
Example messages:
"You have been selected to receive a cash prize" -> spam
"Are we still meeting for dinner tonight?" -> not spam
The trained weights can be saved and loaded later:
torch.save(model.state_dict(), "spam_classifier.pth")
model_state_dict = torch.load("spam_classifier.pth")
model.load_state_dict(model_state_dict)
Common traps¶
Do not confuse the finetuning goals
Pretraining predicts the next token. Classification finetuning predicts a class label. The code may still use the same GPT model, but the target shape and loss interpretation have changed.
Do not treat labels as generated words
The classifier is not generating the word spam. It outputs two numeric logits, then argmax chooses class 0 or class 1.
Class imbalance can hide bad behavior
If most training examples are not spam, a model can look accurate while missing spam. Balancing, class weights, precision, recall, or F1 score may be needed depending on the real goal.
Keep preprocessing consistent
The train, validation, test, and inference paths must use the same tokenizer, maximum length, padding token, and label mapping.
Do not tune on the test set
Validation results can guide learning rate, epochs, and dropout choices. Test results should be kept for the final performance estimate.
Remember train and eval modes
Use model.train() while updating weights and model.eval() during evaluation or inference. This matters for layers such as dropout.
Check yourself¶
Why is classification finetuning usually narrower than instruction finetuning?
Classification finetuning teaches the model to choose among a fixed set of labels. Instruction finetuning teaches broader behavior, such as answering, summarizing, translating, and following natural-language commands.
Why does the notebook balance spam and ham examples?
Because the raw dataset has many more ham messages. Without balancing, the model could get deceptively high accuracy by mostly predicting ham.
Why are SMS messages padded before batching?
A PyTorch batch needs tensors with consistent shapes. Padding makes shorter messages the same length as longer messages.
What changes when model.out_head is replaced?
The model stops producing vocabulary-sized token scores and starts producing two class scores at each token position.
Why does the classifier use model(input_batch)[:, -1, :]?
The last token position can attend to the whole earlier message in a causal GPT model, so it is used as the message-level representation for classification.
Why can prediction skip softmax?
Softmax changes logits into probabilities, but the largest logit remains the largest probability. argmax gives the same class either way.
What part of the model is trained in this notebook?
The new output head is trained, and the notebook also unfreezes the final transformer block and final layer normalization. The earlier blocks and embeddings remain frozen.
Source anchors¶
notebooks/Module2/17-Spam Classification Finetuning.ipynbstudy-guide/drafts/17-spam-classification-finetuning.md