Attention Mechanisms¶
Why this matters¶
Attention is the mechanism that lets a transformer decide which tokens matter for each token it is currently representing. Without attention, a model would have a much weaker way to connect words across a sequence.
For example, in:
The word it needs context. Attention is one way the model can build a richer representation of it by looking back at other tokens and deciding which ones are relevant.
The notebook builds attention in stages: simple self-attention, trainable query/key/value attention, causal masking, dropout, and multi-head attention. This lesson keeps that sequence but focuses on the mechanism instead of every tensor printout.
Mental model¶
Attention is weighted borrowing.
For each token, the model asks:
Which other tokens should influence my current representation, and by how much?
The answer becomes a context vector: a new version of the token embedding enriched with information from other tokens.
The whole process has three recurring steps:
- Score how related tokens are.
- Normalize scores into weights.
- Use the weights to mix information from the tokens.
That is the core of attention.
Core ideas¶
- A token embedding is the model's current numeric representation of a token.
- A context vector is an enriched token representation built by mixing information from other tokens.
- Attention scores are raw compatibility scores between tokens.
- Attention weights are normalized scores, usually produced by softmax, so they behave like proportions.
- Self-attention means the tokens attend to other tokens in the same sequence.
- Trainable attention uses query, key, and value projections.
- Causal attention prevents a token from looking at future tokens.
- Multi-head attention runs several attention mechanisms in parallel so different heads can learn different relationships.
Walkthrough¶
Start with a sequence of token embeddings¶
The notebook uses this sentence:
After tokenization and embedding, each token is represented as a vector. A tiny teaching version could look like this:
| token | embedding |
|---|---|
| Your | [0.43, 0.15, 0.89] |
| journey | [0.55, 0.87, 0.66] |
| starts | [0.57, 0.85, 0.64] |
| with | [0.22, 0.58, 0.33] |
| one | [0.77, 0.25, 0.10] |
| step | [0.05, 0.80, 0.55] |
The numbers are not words anymore. They are vectors. Attention operates on those vectors.
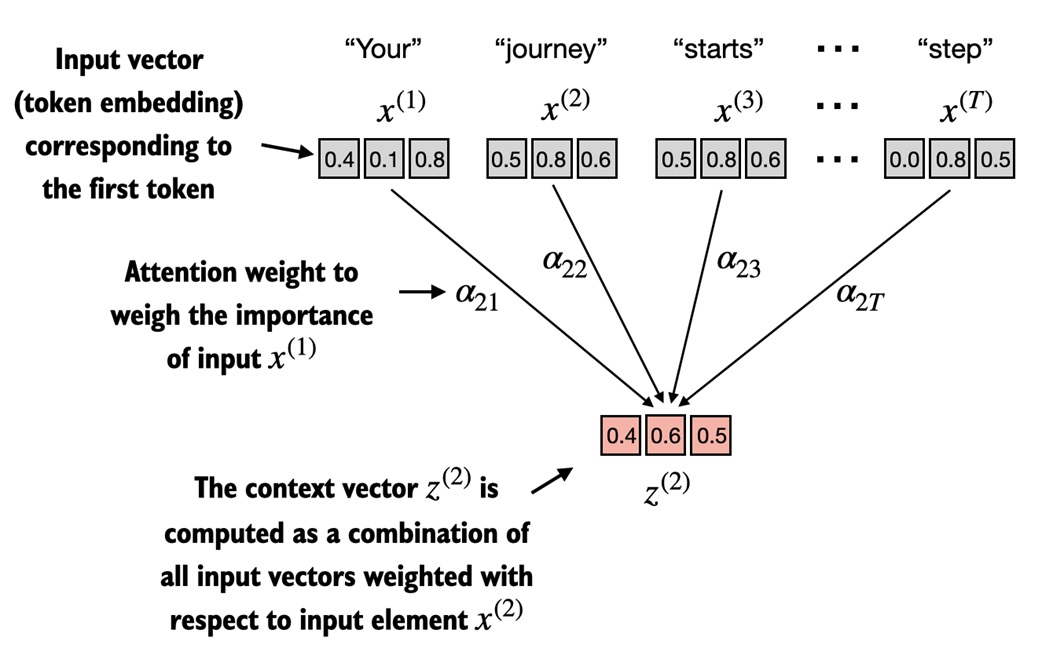
Simple self-attention: score, normalize, mix¶
Suppose we want a context vector for the token journey.
First, compare journey with every token using a dot product. A higher dot product means the vectors point in more similar directions.
These are raw attention scores. They are not yet easy to interpret because they do not sum to 1.
Next, normalize with softmax:
Now the weights are positive and sum to 1. A larger weight means that token contributes more to the context vector for journey.
Finally, mix the input embeddings using those weights:
The result is a new vector for journey. It still represents journey, but now it also contains information borrowed from the other tokens.
Compute attention for every token¶
The previous example computed one context vector. Transformers need one context vector per token.
Instead of looping token by token, we can compute a full score matrix:
Read the shapes conceptually:
inputs: tokens x embedding_size
scores: tokens x tokens
weights: tokens x tokens
contexts: tokens x embedding_size
Each row of weights answers one question:
For this token, how much should I borrow from each token?
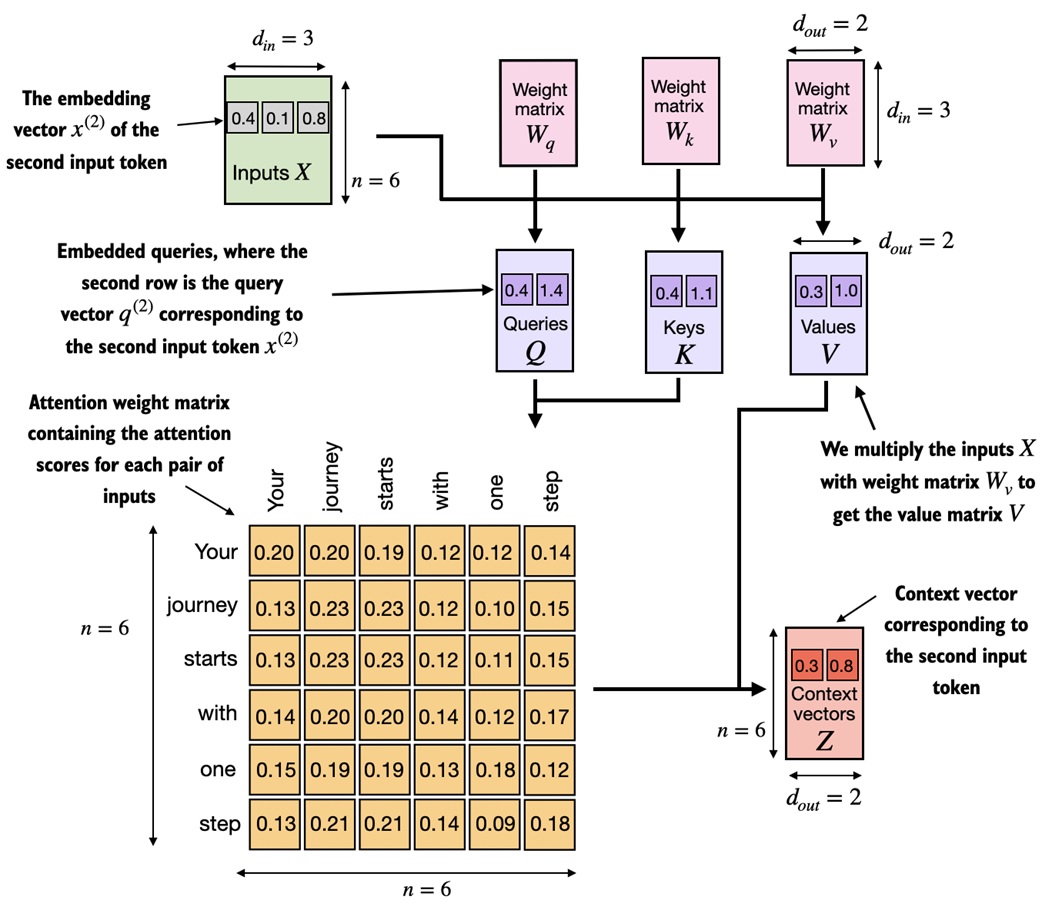
Why query, key, and value exist¶
The simple version compares raw token embeddings directly. Real transformer attention does something more flexible: it learns three projections of each token.
- Query: what this token is looking for
- Key: what this token offers for matching
- Value: what information this token contributes if attended to
A database analogy is useful:
In code, the model learns three linear layers:
Then attention uses:
scores = queries @ keys.transpose(-2, -1)
weights = torch.softmax(scores, dim=-1)
contexts = weights @ values
The model no longer compares raw embeddings directly. It learns how to create the right query, key, and value views during training.
Scaled dot-product attention¶
Transformer attention usually scales the scores before softmax:
scores = queries @ keys.transpose(-2, -1)
scores = scores / keys.shape[-1]**0.5
weights = torch.softmax(scores, dim=-1)
contexts = weights @ values
The scaling keeps scores from becoming too large when the key/query dimension is large. Without scaling, softmax can become too sharp too early, which makes training less stable.
The idea is simple:
Compare queries to keys, scale the scores, softmax them, then mix values.
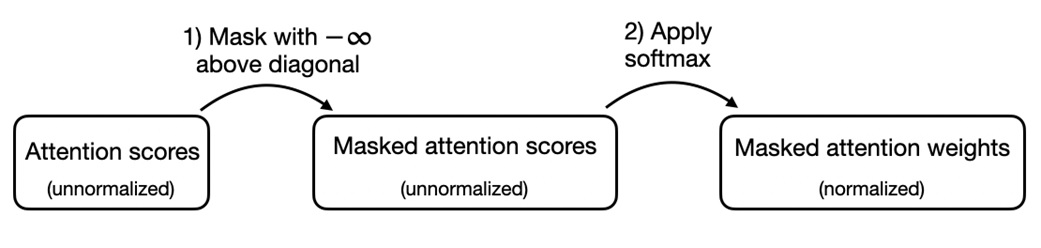
Causal masking: no looking ahead¶
GPT-style models generate text left to right. When predicting the next token, a token should not be allowed to use information from future tokens.
That is what a causal mask enforces.
Without a mask, token 2 can attend to token 5. With a causal mask, token 2 can only attend to tokens 1 and 2.
The efficient implementation masks future positions before softmax:
mask = torch.triu(torch.ones(num_tokens, num_tokens), diagonal=1)
scores = scores.masked_fill(mask.bool(), -torch.inf)
weights = torch.softmax(scores, dim=-1)
Why before softmax? Because softmax turns negative infinity into zero probability. Future tokens get zero attention weight, and the remaining allowed weights still sum to 1.
Dropout in attention¶
The notebook also applies dropout to attention weights. Dropout randomly zeros some weights during training so the model does not rely too heavily on exact paths.
Modern LLM details vary, but the study idea is:
Dropout is a training-time regularization technique. It is not used the same way during inference.
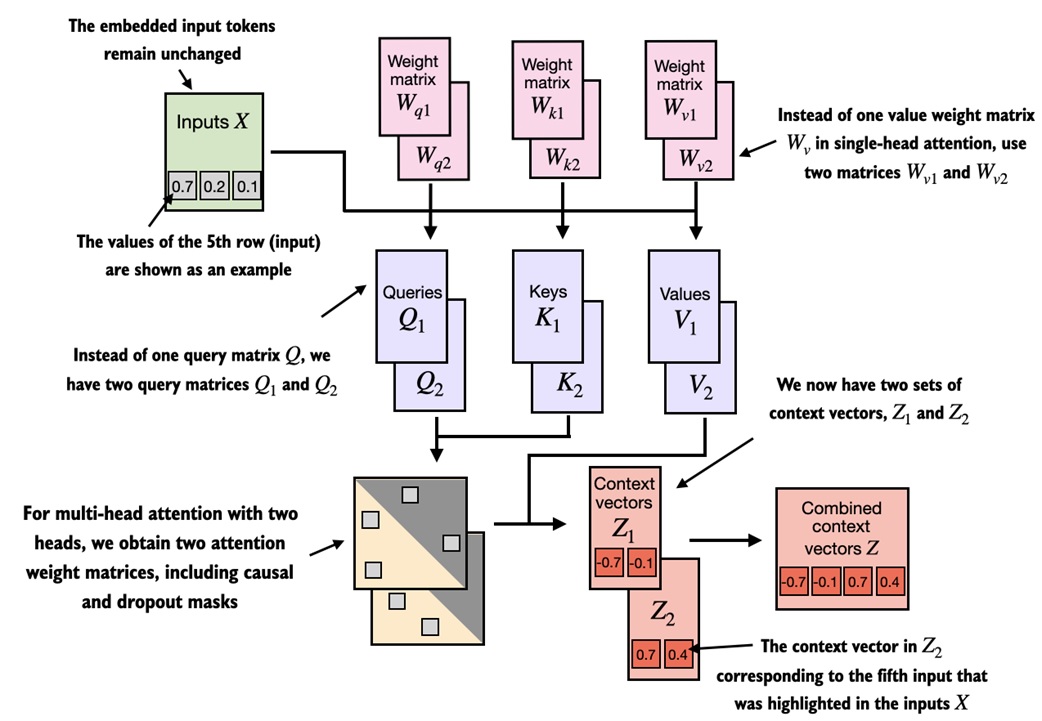
Multi-head attention¶
One attention head gives one way of mixing token information. Multi-head attention runs several attention heads in parallel.
Why? Different heads can learn different relationships:
- one head might track nearby syntax
- one head might track subject-verb relationships
- one head might track positional or phrase-level patterns
The outputs from the heads are combined into one representation.
Conceptually:
head 1: attention view A
head 2: attention view B
head 3: attention view C
combined output = concatenate or project the head outputs
The efficient implementation does not literally need separate Python modules for every head. It usually creates larger query/key/value tensors, reshapes them into a num_heads dimension, performs batched attention, and then merges the heads again.
Explained code examples¶
One compact causal attention block¶
import torch
from torch import nn
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout=0.0):
super().__init__()
self.query = nn.Linear(d_in, d_out, bias=False)
self.key = nn.Linear(d_in, d_out, bias=False)
self.value = nn.Linear(d_in, d_out, bias=False)
self.dropout = nn.Dropout(dropout)
mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)
self.register_buffer("mask", mask)
def forward(self, x):
keys = self.key(x)
queries = self.query(x)
values = self.value(x)
scores = queries @ keys.transpose(1, 2)
scores = scores.masked_fill(
self.mask.bool()[: x.shape[1], : x.shape[1]],
-torch.inf,
)
weights = torch.softmax(scores / keys.shape[-1]**0.5, dim=-1)
weights = self.dropout(weights)
return weights @ values
What this teaches:
query,key, andvalueare learned projections.scorescompares every query with every key.- the mask blocks future tokens.
softmaxturns scores into attention weights.weights @ valuesproduces context vectors.register_bufferstores the mask as part of the module without treating it as a trainable parameter.
Shape checklist¶
For a batch of token embeddings:
x: batch x tokens x input_dimension
queries: batch x tokens x output_dimension
keys: batch x tokens x output_dimension
values: batch x tokens x output_dimension
scores: batch x tokens x tokens
weights: batch x tokens x tokens
output: batch x tokens x output_dimension
This shape checklist is often more useful than memorizing the code. If the dimensions make sense, the attention computation is easier to debug.
Multi-head attention shape idea¶
Multi-head attention adds a head dimension:
before split: batch x tokens x output_dimension
after split: batch x heads x tokens x head_dimension
Each head performs attention separately. Then the heads are merged back:
The code looks complex because of reshaping and transposing, but the concept is still:
split into heads, run attention per head, combine heads.
Common traps¶
Attention means the model understands words like humans do.
Attention is a learned weighting mechanism over vectors. It can support useful behavior, but it is not human understanding by itself.
Attention weights and attention scores are the same thing.
Scores are raw compatibility values. Weights are normalized scores after softmax.
The value vector is used to decide what to attend to.
Queries and keys decide the weights. Values provide the information that gets mixed.
Causal attention is optional in GPT-style generation.
For left-to-right language modeling, causal masking is essential. Without it, training would let tokens see future answers.
Mask after softmax is equivalent.
Masking before softmax is cleaner because masked positions become zero probability and allowed positions still normalize correctly.
Multi-head attention is a totally different algorithm.
It is the same attention idea run in parallel across multiple learned subspaces.
Tensor reshaping is the concept.
Reshaping is implementation plumbing. The concept is scoring, normalizing, mixing, and doing that across multiple heads.
Check yourself¶
What is a context vector?
A context vector is an enriched representation of a token, created by mixing information from other token representations using attention weights.
What are the three recurring steps in attention?
Compute scores, normalize them into weights, then use the weights to mix value vectors.
What is the difference between attention scores and attention weights?
Scores are raw compatibility values. Weights are normalized scores, usually after softmax, and they sum to 1 across the attended tokens.
In query-key-value attention, which vectors decide the attention weights?
Queries and keys. Their similarity produces the attention scores.
What role do value vectors play?
Values are the information that gets combined after the attention weights are computed.
Why does GPT-style attention need a causal mask?
It prevents each token from attending to future tokens, preserving left-to-right generation.
Why are attention scores scaled before softmax?
Scaling keeps scores from becoming too large as the key/query dimension grows, which helps training stability.
What is the main idea of multi-head attention?
Run several attention heads in parallel so the model can learn different relationship patterns, then combine their outputs.
Source anchors¶
- Source file:
notebooks/Module2/13-Attention Mechanisms.ipynb - Source basis: Sebastian Raschka, Build a Large Language Model From Scratch, chapter 3 materials
- Key source concepts: simple self-attention, context vectors, attention scores, attention weights, softmax, query/key/value projections, scaled dot-product attention, causal masking, dropout, compact causal attention class, multi-head attention, tensor reshaping
- Source images:
study-guide/docs/assets/extracted/simpleattn.jpg,study-guide/docs/assets/extracted/selfattn.jpg,study-guide/docs/assets/extracted/masking3.jpg,study-guide/docs/assets/extracted/multihd.jpg