Working with Text¶
Why this matters¶
Neural networks do not process raw text directly. They process numbers. Before a GPT-like model can learn from a story, article, or conversation, the text must go through a pipeline:
This lesson explains that pipeline. It is the bridge between the PyTorch basics and the attention/GPT lessons.
Mental model¶
Think of text preparation as translation into the model's native language.
- Tokenization cuts text into pieces.
- A vocabulary maps pieces to integer IDs.
- A data loader creates input and target sequences.
- Embedding layers turn IDs into trainable vectors.
- Positional embeddings tell the model where each token is located.
The final result is not text anymore. It is a tensor that a neural network can process.
Core ideas¶
- LLMs are trained on next-token prediction.
- Tokenization splits text into words, subwords, punctuation, or special symbols.
- For LLMs, we usually do not lowercase, stem, or remove stop words.
- A vocabulary maps tokens to integer IDs.
- Unknown words are a problem for simple vocabularies.
- Special tokens such as
<|unk|>and<|endoftext|>carry extra meaning. - Byte pair encoding, or BPE, handles unseen words by using subword pieces.
tiktokenprovides a fast GPT-style BPE tokenizer.- GPT training examples are made by shifting targets one token ahead.
- A sliding window turns one long text into many input-target examples.
- Token embeddings convert token IDs into vectors.
- Positional embeddings add order information.
Walkthrough¶
Why text needs preparation¶
Earlier neural-network lessons used numeric data: pixels, flower measurements, or small tensors. Text is different:
A neural network cannot multiply strings by weights. The text must become IDs and then vectors.
The notebook uses Edith Wharton's public-domain short story The Verdict as a small training text.
Tokenization¶
Tokenization breaks text into pieces.
For example:
can become:
The notebook first builds a simple tokenizer with regular expressions:
import re
text = "Hello, world. Is this-- a test?"
tokens = re.split(r'([,.:;?_!"()\']|--|\s)', text)
tokens = [item.strip() for item in tokens if item.strip()]
What this teaches:
- punctuation should often become separate tokens
- whitespace can be used as a splitting boundary
- capitalization is preserved because it carries information
- LLM preprocessing is not the same as classic bag-of-words preprocessing
In LLMs, we usually avoid stemming and stop-word removal because the model needs to learn natural text structure.
Vocabulary and token IDs¶
After tokenization, each unique token gets an integer ID.
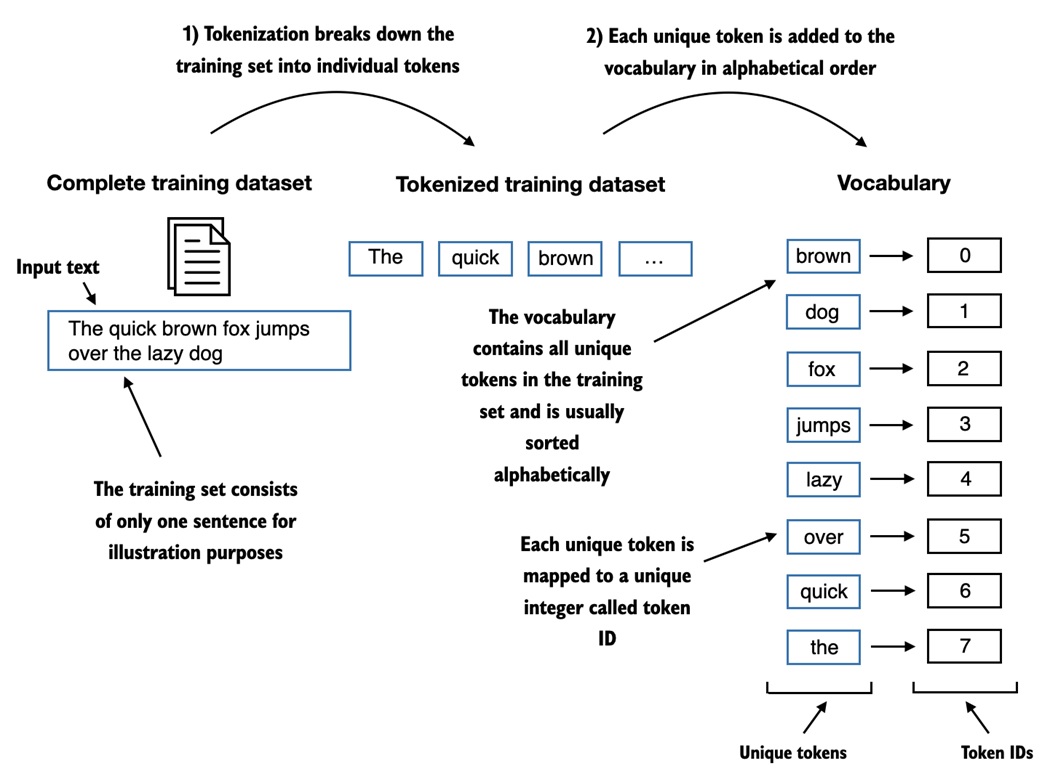
Example:
The notebook builds a vocabulary from all unique tokens:
all_words = sorted(set(preprocessed))
vocab = {token: integer for integer, token in enumerate(all_words)}
This gives a lookup table from string token to integer ID.
Encoding and decoding¶
A tokenizer needs two directions:
Simplified tokenizer:
class SimpleTokenizerV1:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i: s for s, i in vocab.items()}
def encode(self, text):
tokens = re.split(r'([,.?_!"()\']|--|\s)', text)
tokens = [item.strip() for item in tokens if item.strip()]
return [self.str_to_int[token] for token in tokens]
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
return re.sub(r'\s+([,.?!"()\'])', r'\1', text)
What this teaches:
encodeis needed before model inputdecodeis needed after model output- decoding also needs small cleanup rules, such as removing spaces before punctuation
Unknown tokens¶
A simple vocabulary fails when it sees a token that was not in the training text.
If Hello never appeared in The Verdict, then this fails:
The notebook fixes this first by adding special tokens:
The tokenizer can then replace unknown tokens with <|unk|>.
That is better than crashing, but it loses information. If Hello and palace both become <|unk|>, the model cannot tell them apart.
Byte pair encoding¶
Byte pair encoding, or BPE, solves the unknown-word problem more gracefully.
Instead of requiring every full word to exist in the vocabulary, BPE can split words into subword pieces.
The exact split depends on the tokenizer's learned vocabulary and merge rules.
The notebook uses OpenAI's tiktoken package with the GPT-2 encoding:
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
ids = tokenizer.encode(
"Hello, do you like tea? <|endoftext|> In the sunlit terraces",
allowed_special={"<|endoftext|>"},
)
text = tokenizer.decode(ids)
What this teaches:
- BPE can represent unfamiliar words as smaller pieces
- GPT-style tokenizers include special tokens
- token IDs are model-specific, not universal
- decoding turns token IDs back into readable text
Next-token prediction¶
LLMs are trained to predict the next token.
If the input tokens are:
the target is the next token:
For a sequence of token IDs, the targets are just shifted one position to the right:
This is the key training setup for GPT-like models.
Sliding windows¶
One long text can produce many training examples.

With max_length=4 and stride=1, the windows overlap heavily:
window 1 input: tokens 0..3
window 1 target: tokens 1..4
window 2 input: tokens 1..4
window 2 target: tokens 2..5
With stride=4, the windows do not overlap:
The trade-off:
- smaller stride gives more examples but more overlap
- larger stride gives fewer examples and less repetition
GPT dataset class¶
The notebook builds a PyTorch Dataset that turns raw text into input-target token chunks.
from torch.utils.data import Dataset
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1:i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
What this teaches:
- each dataset row is one training example
- inputs and targets have the same length
- targets are shifted by one token
- the dataset stores token IDs, not raw strings
DataLoader for text¶
Wrap the dataset in a DataLoader:
from torch.utils.data import DataLoader
def create_dataloader_v1(
txt,
batch_size=4,
max_length=256,
stride=128,
shuffle=True,
drop_last=True,
num_workers=0,
):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers,
)
If batch_size=8 and max_length=4, the input tensor shape is:
That means:
The target tensor has the same shape.
Token embeddings¶
Token IDs are integers. Neural networks need dense vectors.
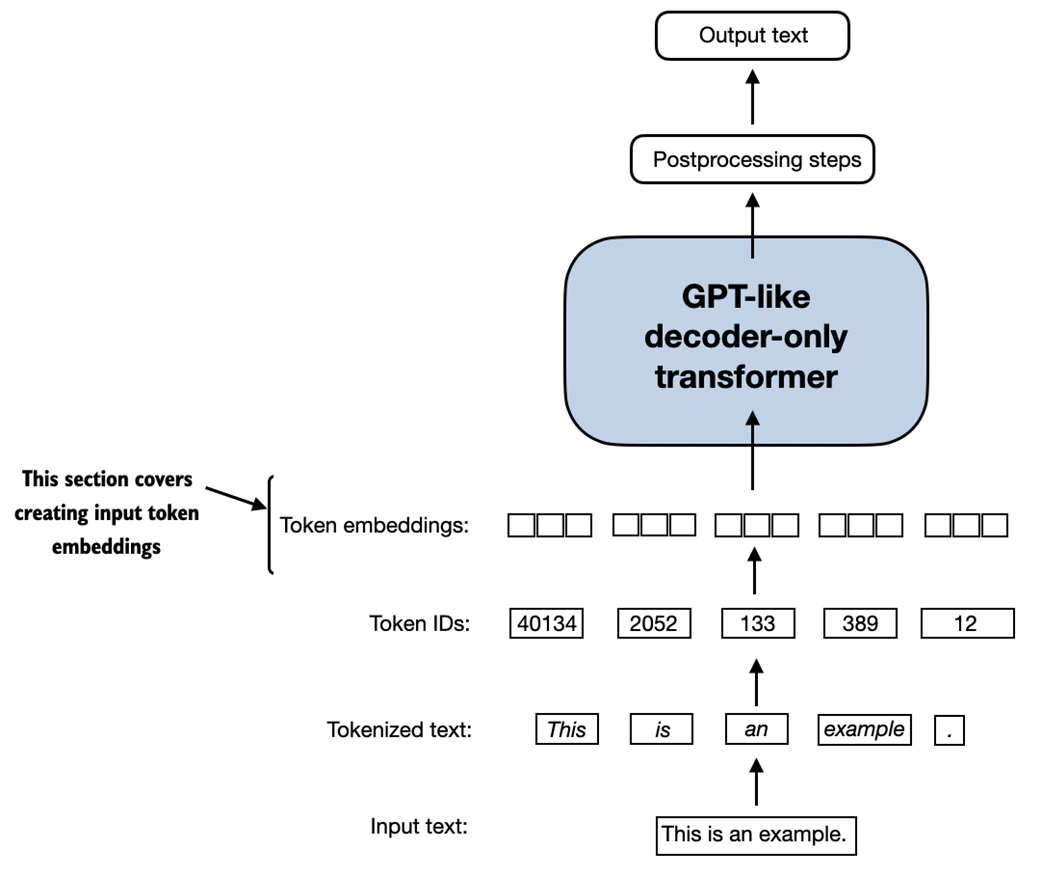
PyTorch uses an embedding layer as a lookup table:
import torch
vocab_size = 50257
output_dim = 256
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
token_embeddings = token_embedding_layer(inputs)
If inputs has shape:
then token_embeddings has shape:
That means:
The embedding weights start random and are learned during training.
Embeddings are lookup rows¶
An embedding layer is essentially a table.
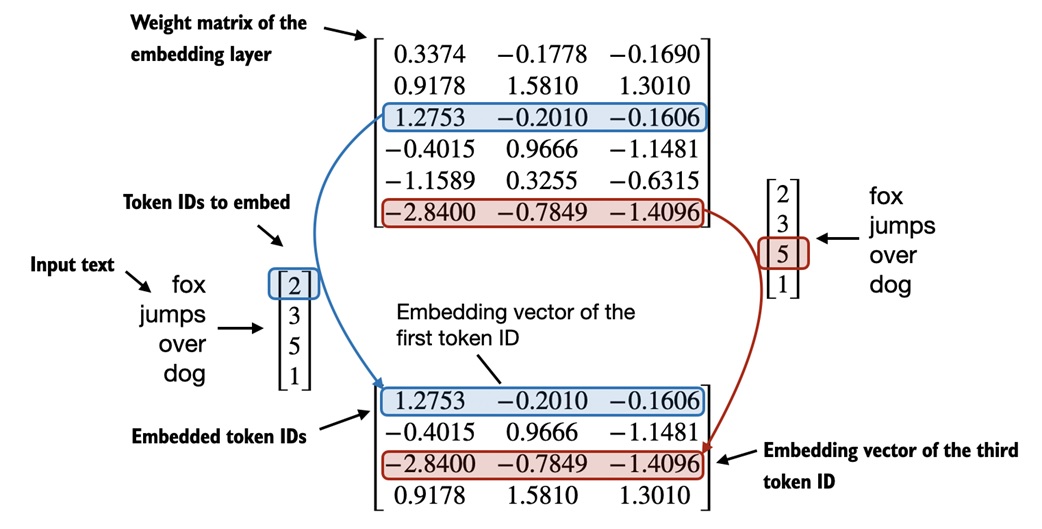
If token ID 5 is passed into the embedding layer, PyTorch returns row 5 of the embedding matrix.
This is why token IDs must stay within the vocabulary size. If the vocabulary has 50,257 tokens, valid IDs are from 0 to 50256.
Positional embeddings¶
Token embeddings alone do not tell the model where a token appeared.
The same token gets the same token embedding whether it appears first or fourth:
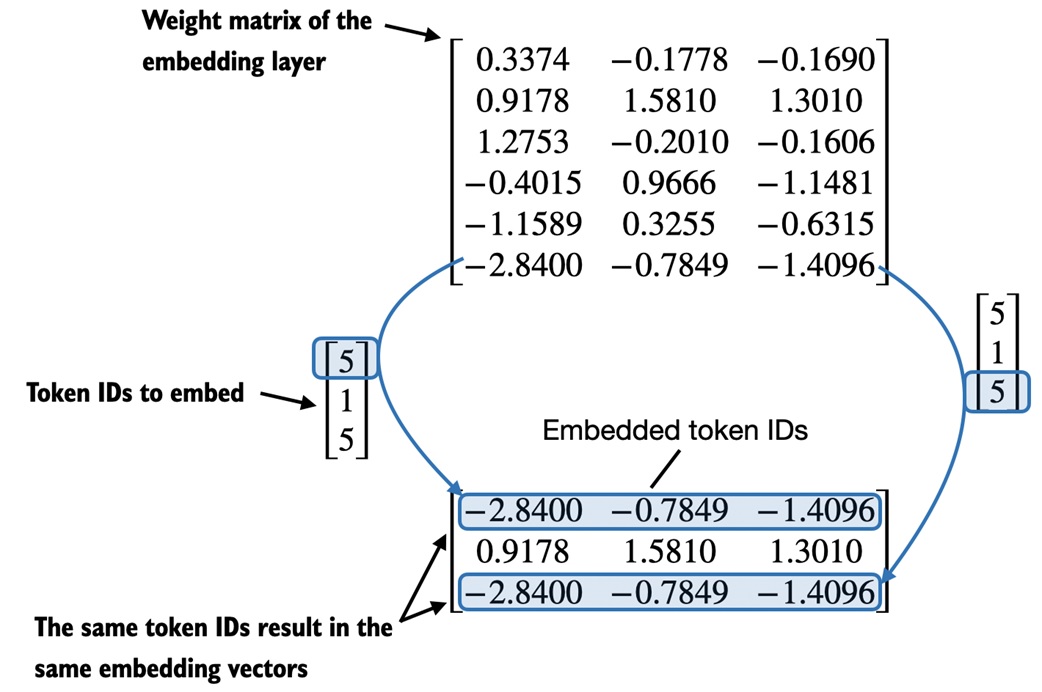
GPT-style models need position information, so the notebook adds positional embeddings:
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
input_embeddings = token_embeddings + pos_embeddings
The shapes are:
PyTorch broadcasts the [4, 256] positional tensor across the 8 batch examples.
Final input pipeline¶
The full input pipeline is:
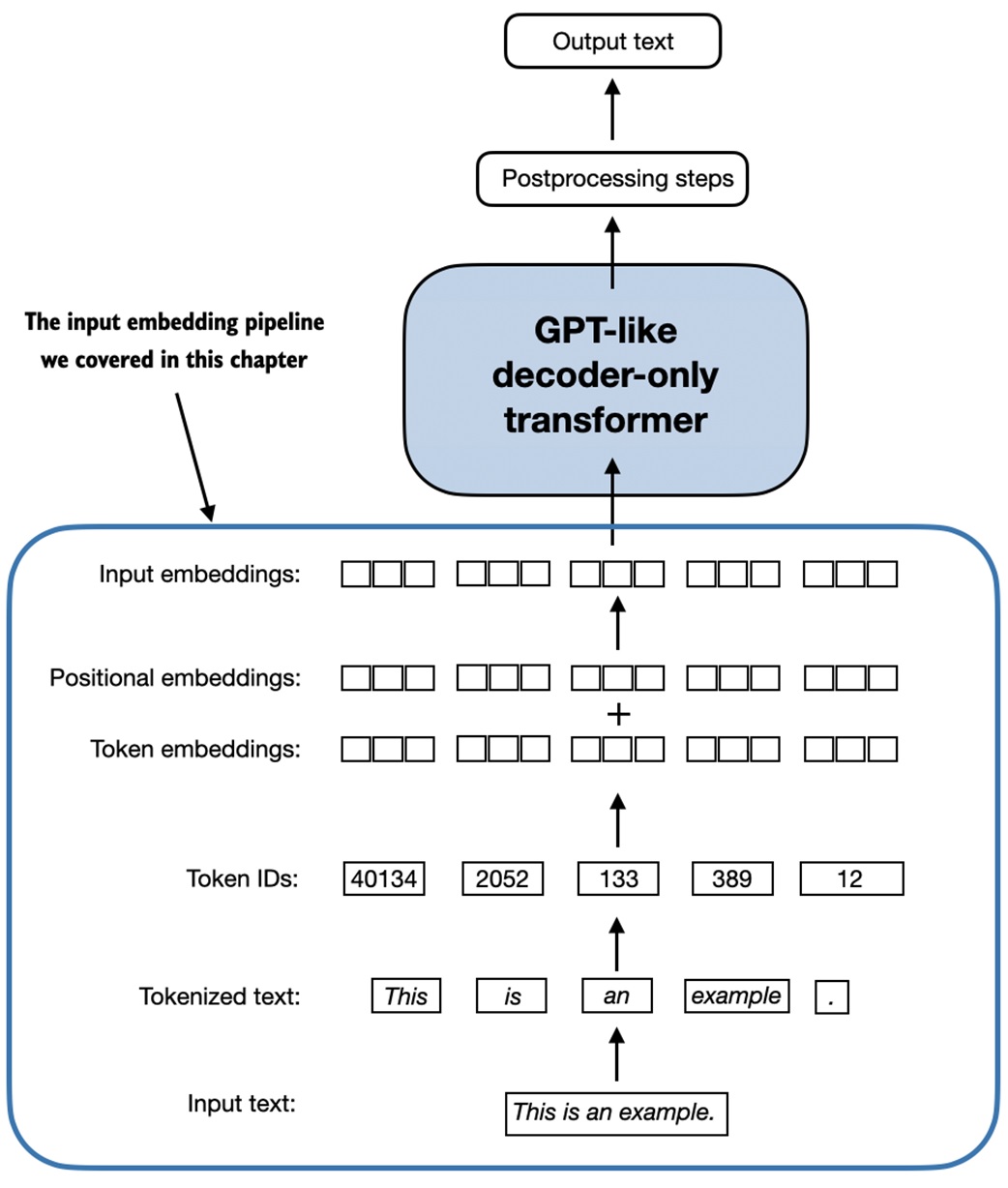
raw text
-> BPE tokenizer
-> token IDs
-> sliding-window input-target pairs
-> token embeddings
-> token embeddings plus positional embeddings
-> LLM layers
This is what prepares text for attention and transformer blocks.
Common traps¶
LLM tokenization is just splitting on spaces.
Modern tokenizers usually use subword pieces and punctuation handling. Space splitting is only a teaching simplification.
Lowercasing and stop-word removal are always good preprocessing.
For LLM training, those transformations usually remove useful information.
Token IDs have meaning by themselves.
Token IDs are just lookup indices. The learned embedding vectors carry the useful representation.
Unknown tokens are harmless.
A single <|unk|> token hides differences between many unseen words.
BPE understands words like a human.
BPE follows learned subword merge rules. It is practical, not semantic by itself.
Targets are separate labels someone wrote by hand.
For next-token prediction, targets are created automatically by shifting the input text by one token.
Token embeddings already encode word order.
Token embeddings identify tokens. Positional embeddings add order information.
Check yourself¶
Why do we tokenize text before training an LLM?
The model needs numeric inputs. Tokenization breaks text into units that can be mapped to token IDs.
Why does the simple tokenizer fail on unseen words?
Its vocabulary only contains tokens seen in the training text. Unknown tokens have no ID unless special handling is added.
What does <|endoftext|> represent?
It marks a boundary between separate pieces of text, helping the model learn where one document or sample ends.
Why is BPE useful?
It can represent unfamiliar words using subword or character-level pieces instead of collapsing everything into <|unk|>.
How are next-token targets created?
The target sequence is the input sequence shifted one token to the right.
What does stride control in the text dataset?
It controls how far the sliding window moves between training examples.
What does an embedding layer do?
It looks up a trainable vector for each token ID.
Why add positional embeddings?
They give the model information about token order, which token embeddings alone do not provide.
Source anchors¶
This lesson rewrites the main ideas from 12-Working with Text.ipynb:
- LLM text preparation pipeline
- tokenization with regular expressions
- vocabulary construction and token IDs
- encode/decode tokenizer classes
- special tokens
<|unk|>and<|endoftext|> - BPE tokenization with
tiktoken - next-token prediction targets
- sliding-window text dataset
- PyTorch
DatasetandDataLoaderfor GPT-style training data - token embeddings and positional embeddings