Implementing a GPT Model¶
Why this matters¶
The earlier LLM lessons introduced the ingredients separately:
This lesson assembles those pieces into a GPT-style model architecture. The model is not trained yet, so its generated text is still random-looking. But the structure is now in place:
token embeddings
+ positional embeddings
-> repeated transformer blocks
-> final normalization
-> vocabulary logits
-> generated token IDs
Mental model¶
A GPT model is a stack of repeated blocks.
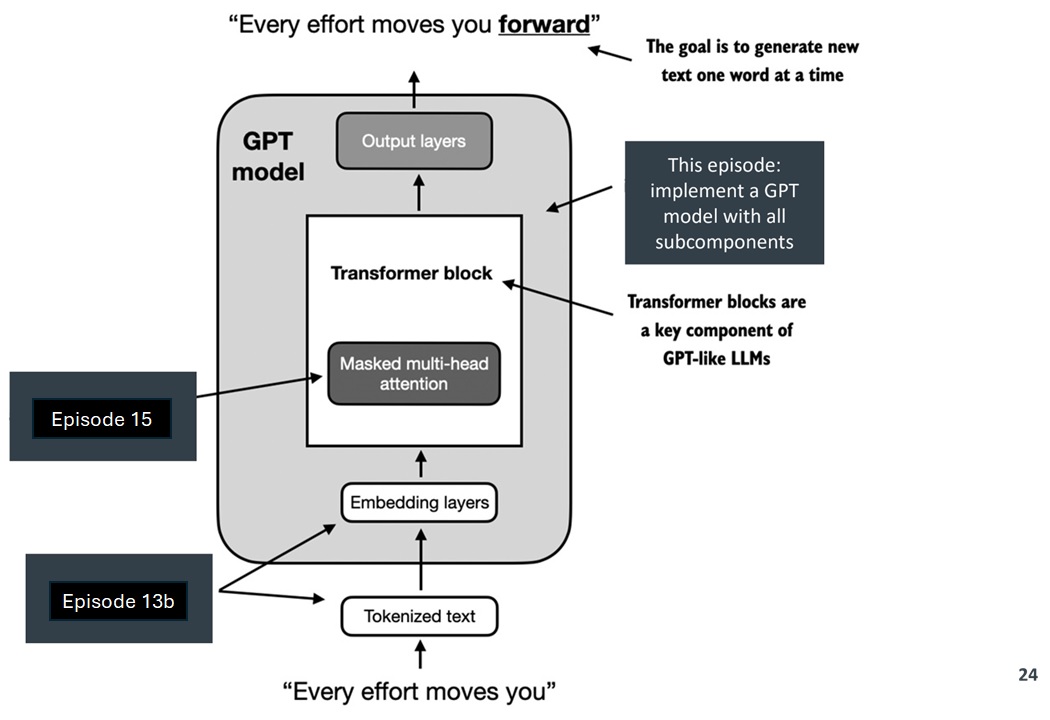
Each block has the same broad job:
- attention mixes information across tokens
- feed-forward layers transform each token representation
- layer normalization stabilizes values
- shortcut connections help gradients flow
- dropout regularizes training
The architecture is large because these blocks are repeated many times, not because every part is conceptually different.
Core ideas¶
- GPT is a decoder-only transformer model for next-token prediction.
- Input token IDs are converted into token embeddings and positional embeddings.
- The model uses masked multi-head attention so each token can only attend to current and previous tokens.
- Layer normalization stabilizes activations.
- GELU is the activation function used in the feed-forward subnetwork.
- The feed-forward subnetwork expands the embedding dimension and then compresses it back.
- Shortcut connections add a block's input back to its output.
- A transformer block combines attention, feed-forward layers, normalization, dropout, and shortcuts.
- The final output head maps hidden vectors back to vocabulary-sized logits.
- Greedy decoding repeatedly selects the highest-scoring next token.
- An untrained GPT architecture can run, but it will generate incoherent text.
Walkthrough¶
GPT-2 small configuration¶
The notebook implements the shape of the smallest GPT-2 model.
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False,
}
Read these settings as:
- vocabulary size: how many token IDs the tokenizer can produce
- context length: maximum number of input tokens the model can consider
- embedding dimension: vector size for each token
- attention heads: how many attention subspaces each block uses
- layers: how many transformer blocks are stacked
- dropout rate: probability of dropping activations during training
- query/key/value bias: whether attention projection layers use bias terms
Placeholder GPT model¶
The notebook first builds a dummy GPT model to show the full skeleton before filling in the real pieces.
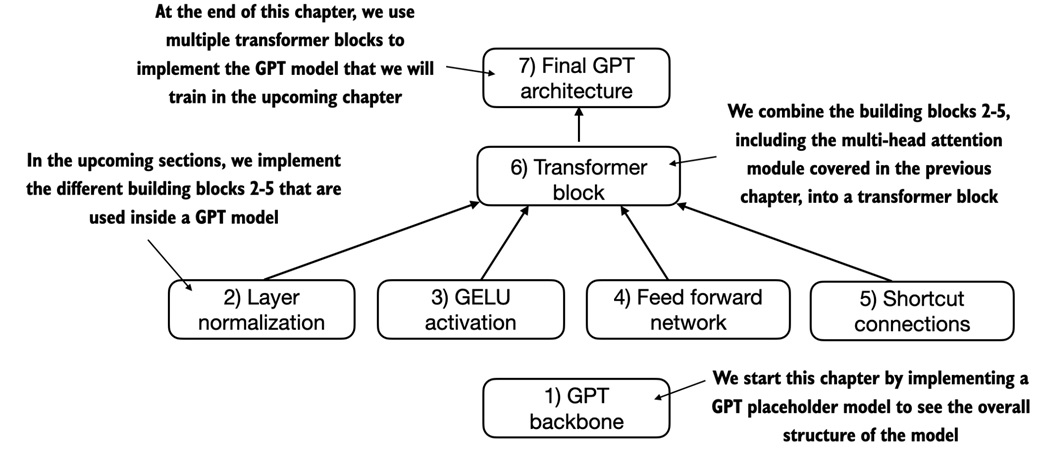
The skeleton is:
class DummyGPTModel(nn.Module):
def __init__(self, cfg):
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = ...
self.final_norm = ...
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
The forward pass does this:
token IDs
-> token embeddings
+ position embeddings
-> dropout
-> transformer blocks
-> final layer normalization
-> output head
-> logits
The output shape for a batch is:
For example, two texts with four tokens each produce:
Each token position gets a score for every possible next token in the vocabulary.
Layer normalization¶
Layer normalization normalizes each token representation across its embedding dimension.
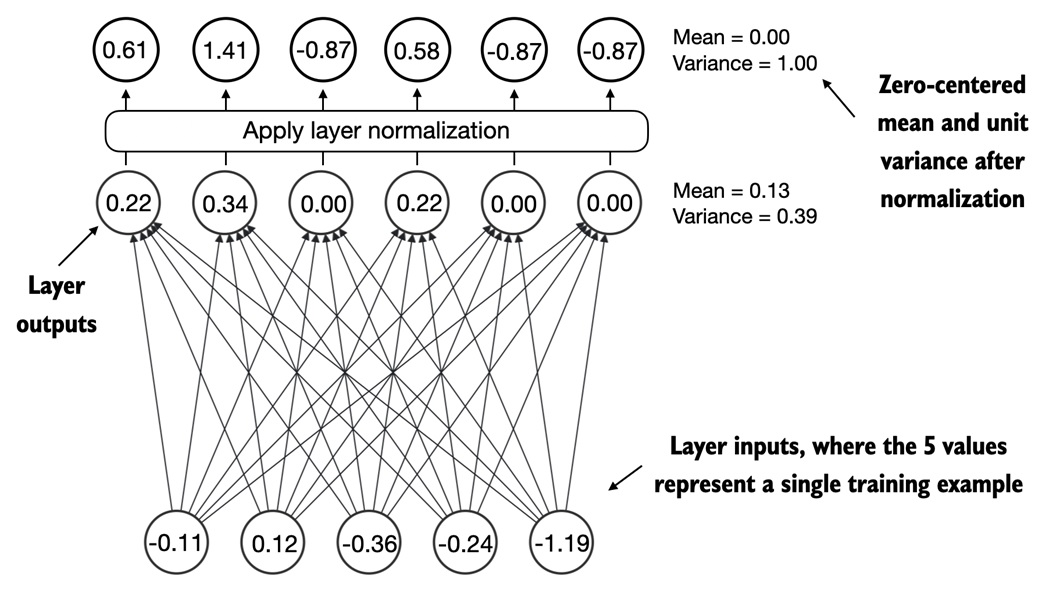
Plain version:
for each token vector:
subtract its mean
divide by its standard deviation
apply learned scale and shift
In code:
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
What this teaches:
- normalization happens over the last dimension
epsprevents division by zeroscaleandshiftare trainable- GPT-style layer norm uses biased variance for compatibility with GPT-2 behavior
GELU and feed-forward layers¶
Transformers use a small feed-forward network inside each block.
The notebook uses GELU as the activation. GELU is smoother than ReLU and was used in GPT-2.
The feed-forward module:
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
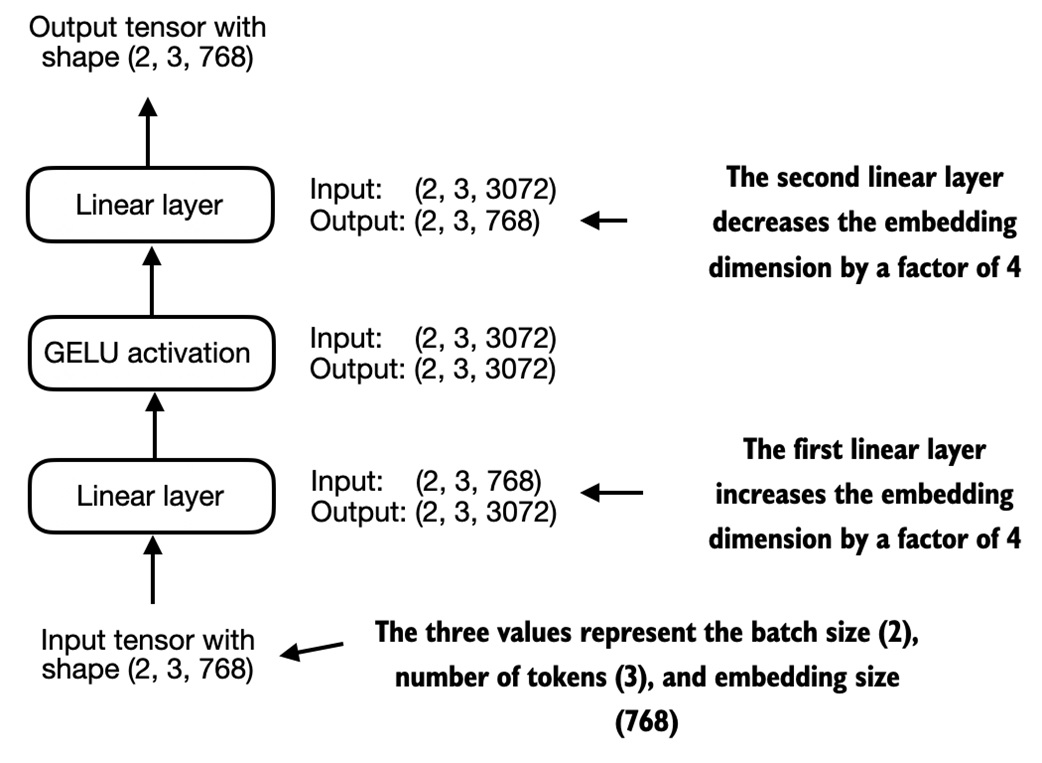
For GPT-2 small:
The sequence length and batch size stay the same. Only the per-token vector is transformed.
Shortcut connections¶
Shortcut connections, also called residual connections, add a module's input back to its output.
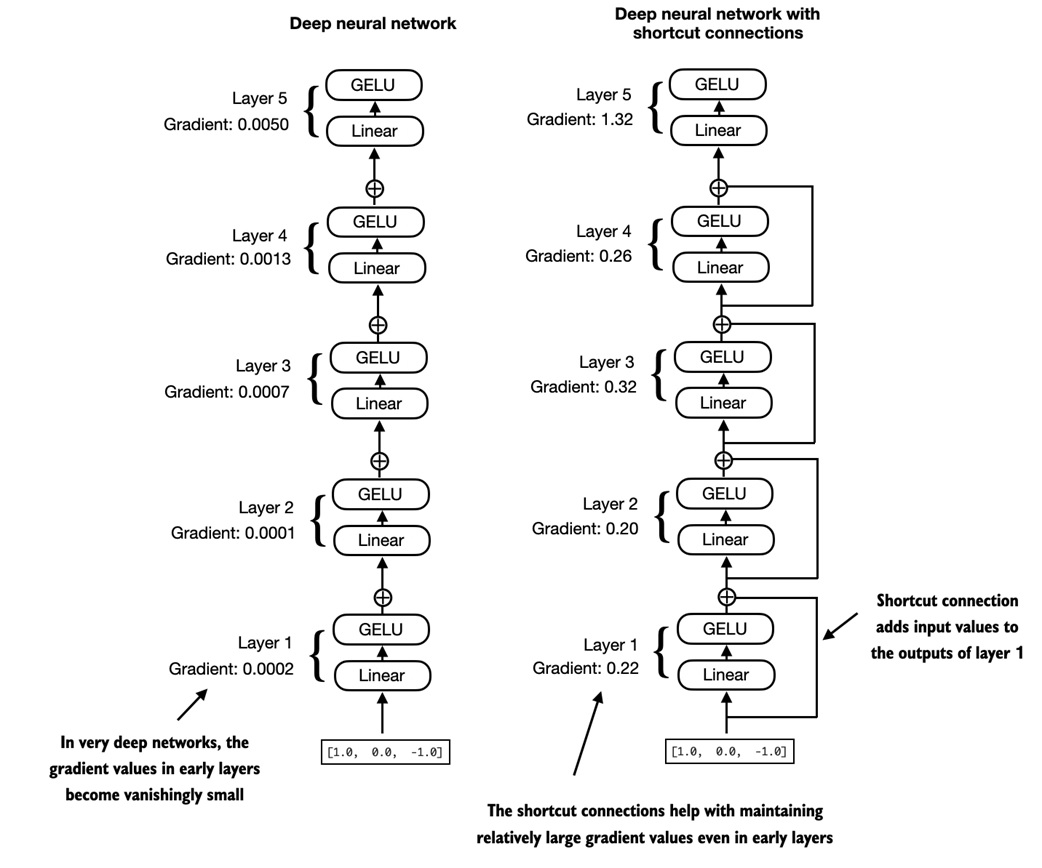
Plain version:
Why this helps:
- gradients have a shorter path through deep networks
- early layers receive stronger learning signals
- many transformer blocks can be stacked more reliably
The important constraint is shape: shortcut addition works when the input and output tensors have the same shape.
Transformer block¶
A transformer block combines the pieces:
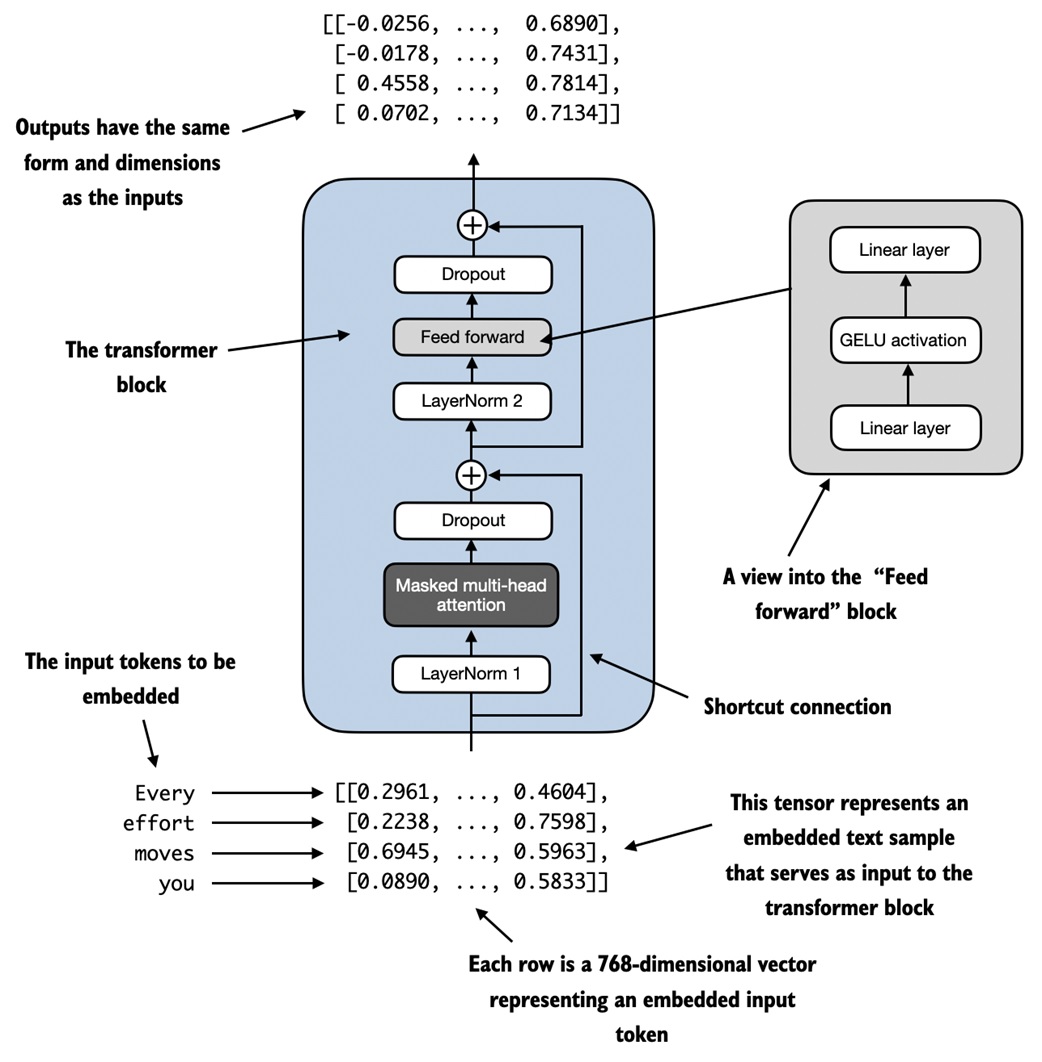
The notebook's block has this structure:
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(...)
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
x = x + shortcut
shortcut = x
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut
return x
Read it as:
normalize -> attention -> dropout -> residual add
normalize -> feed-forward -> dropout -> residual add
This is a pre-layer-normalization transformer block: normalization happens before attention and before the feed-forward network.
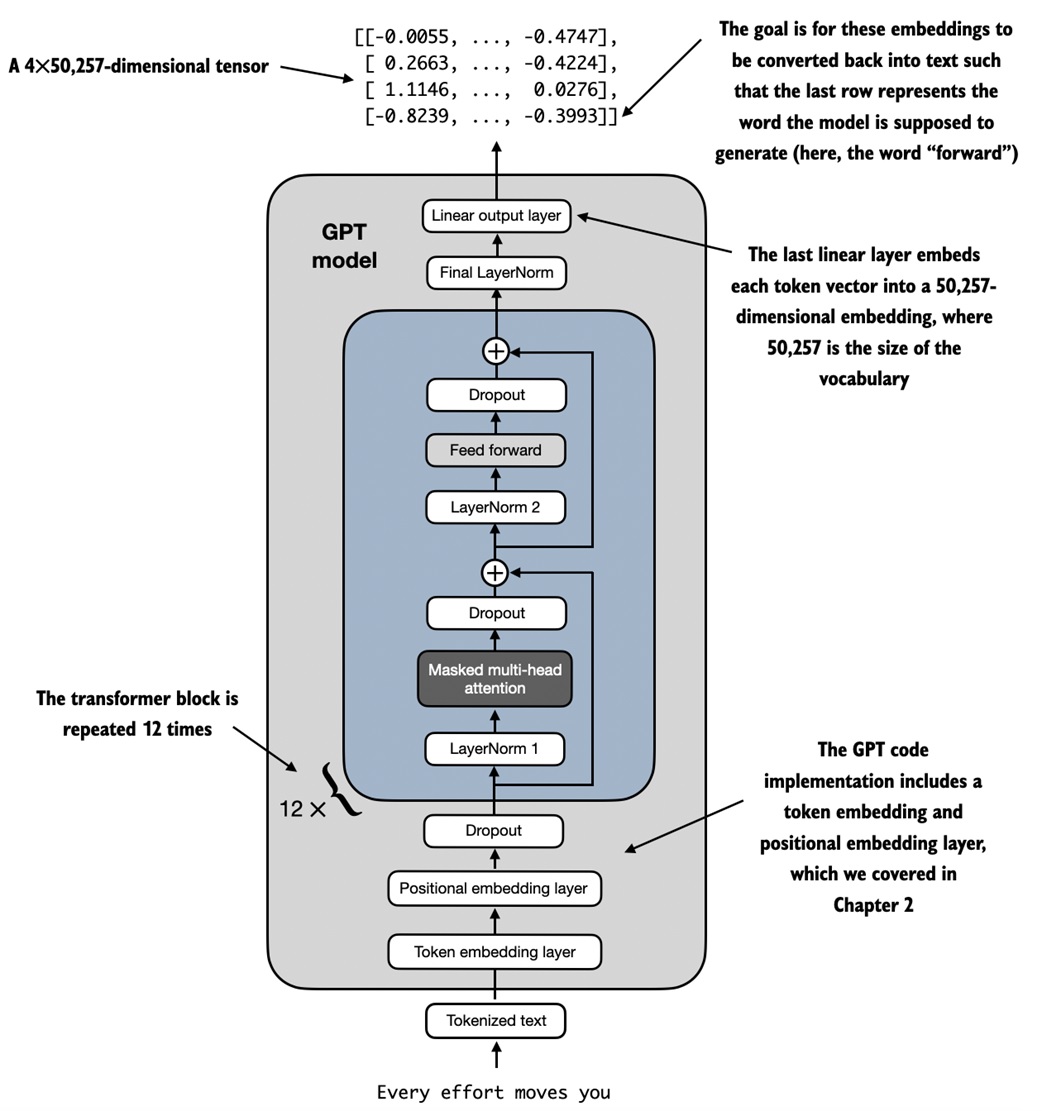
Full GPT model¶
The full model replaces the placeholders with real transformer blocks and layer normalization.
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
self.final_norm = LayerNorm(cfg["emb_dim"])
self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx)
pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
x = tok_embeds + pos_embeds
x = self.drop_emb(x)
x = self.trf_blocks(x)
x = self.final_norm(x)
logits = self.out_head(x)
return logits
What this teaches:
- token and position embeddings are inside the model
- transformer blocks are repeated with
nn.Sequential - final logits are vocabulary-sized scores
- the model predicts next-token scores for every position in the input sequence
Parameter count and weight tying¶
The notebook counts model parameters and finds a subtle point:
The implementation has more parameters than the original GPT-2 small count because the token embedding matrix and output head are separate.
Original GPT-2 used weight tying:
This reduces parameter count because both matrices have the same shape:
The notebook keeps them separate for clarity and flexibility.
Generating text¶
Generation uses the model repeatedly.
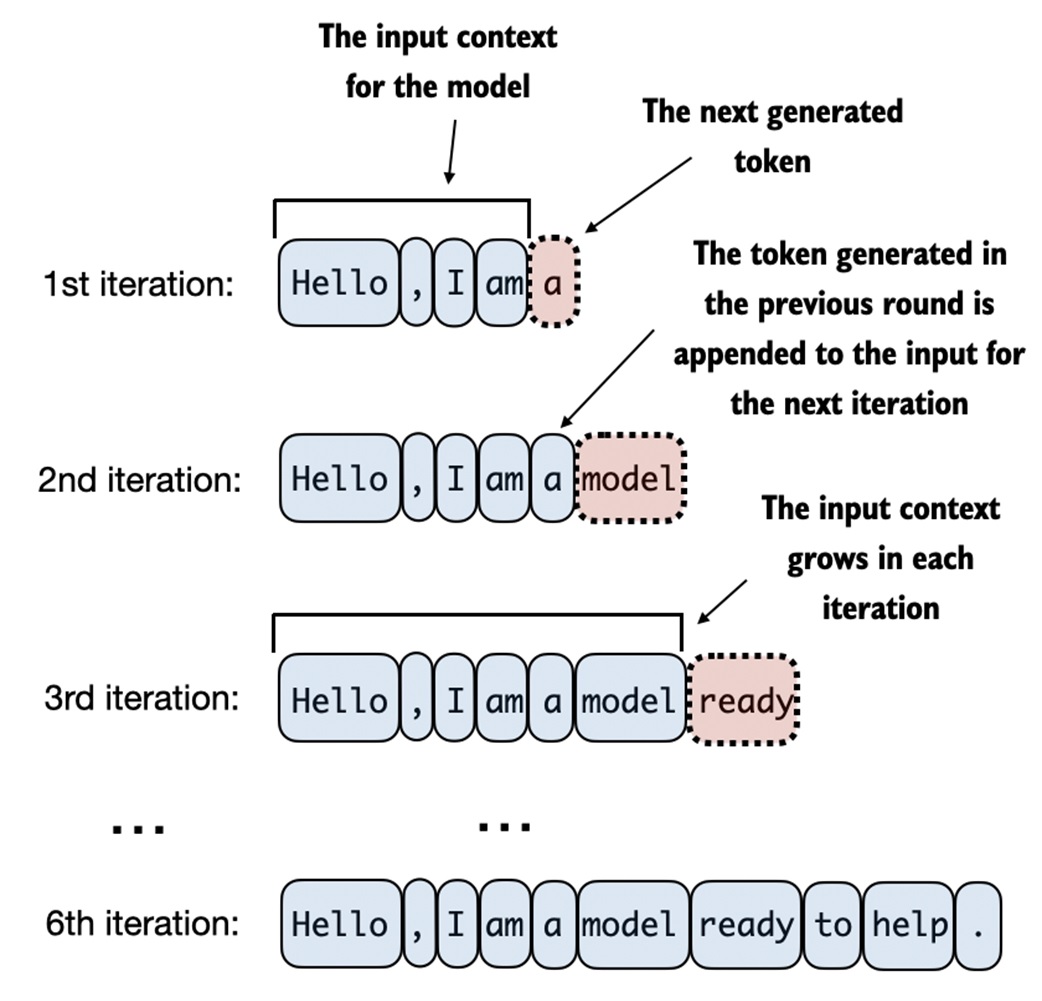
Each iteration:
- Take the current token IDs.
- Crop to the model's context length if needed.
- Run the model.
- Keep only the logits at the last token position.
- Select the next token ID.
- Append that token ID to the sequence.
Greedy generation:
def generate_text_simple(model, idx, max_new_tokens, context_size):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1)
idx_next = torch.argmax(probas, dim=-1, keepdim=True)
idx = torch.cat((idx, idx_next), dim=1)
return idx
The softmax is shown for intuition. For greedy decoding, argmax on logits would choose the same token because softmax preserves ordering.
Why the output is gibberish¶
The notebook runs generation before training.
That is expected to produce incoherent text because the weights are still random:
The next step in the course is training the model so that the logits become useful next-token predictions.
Common traps¶
A GPT architecture is already an intelligent model.
Architecture alone is not enough. Without trained weights, generation is essentially random.
The output dimension is the embedding dimension.
The final logits dimension is the vocabulary size, because the model scores every possible next token.
Layer normalization has no learned parameters.
It normalizes values, but also has trainable scale and shift parameters.
The feed-forward network changes the sequence length.
It transforms each token vector independently and preserves batch size, token count, and final embedding dimension.
Residual connections are optional decoration.
They are central to training deep transformer stacks reliably.
Softmax is required before greedy argmax.
It is useful for interpreting probabilities, but argmax on logits gives the same selected token.
Context length means generated text length.
Context length is the maximum number of previous tokens the model can condition on at once.
Check yourself¶
What does the GPT model receive as input?
It receives batches of token IDs, not raw text strings.
Why are token embeddings and positional embeddings added?
Token embeddings identify what the tokens are. Positional embeddings tell the model where they occur in the sequence.
What does the output head produce?
It maps each final token representation to vocabulary-sized logits.
Why does the output tensor have shape [batch, tokens, vocab_size]?
The model produces next-token scores for every token position in every batch example.
Why is layer normalization used?
It stabilizes activations and makes deep network training more reliable.
What is the role of the feed-forward network inside a transformer block?
It transforms each token representation through an expanded nonlinear hidden space and then returns it to the embedding dimension.
Why do transformer blocks use shortcut connections?
They help gradients flow through deep stacks and preserve useful information across sublayers.
Why does the untrained model generate gibberish?
Its weights are random, so its logits do not yet encode learned language patterns.
Source anchors¶
This lesson rewrites the main ideas from 15-Implementing a GPT Model.ipynb:
- GPT-2 small configuration
- placeholder GPT architecture
- token and positional embeddings inside the model
- layer normalization
- GELU activation and feed-forward network
- shortcut/residual connections
- transformer block assembly
- full GPT model class
- parameter counting and weight tying
- greedy text generation from logits