Generating Text with a Pre-Trained LLM¶
Why this matters¶
Before improving reasoning, we need a working generation loop.
This lesson loads a small pre-trained Qwen3 model and implements the basic mechanics of text generation:
The key idea is simple: an LLM writes one token at a time.
Mental model¶
Autoregressive generation is repeated next-token prediction.
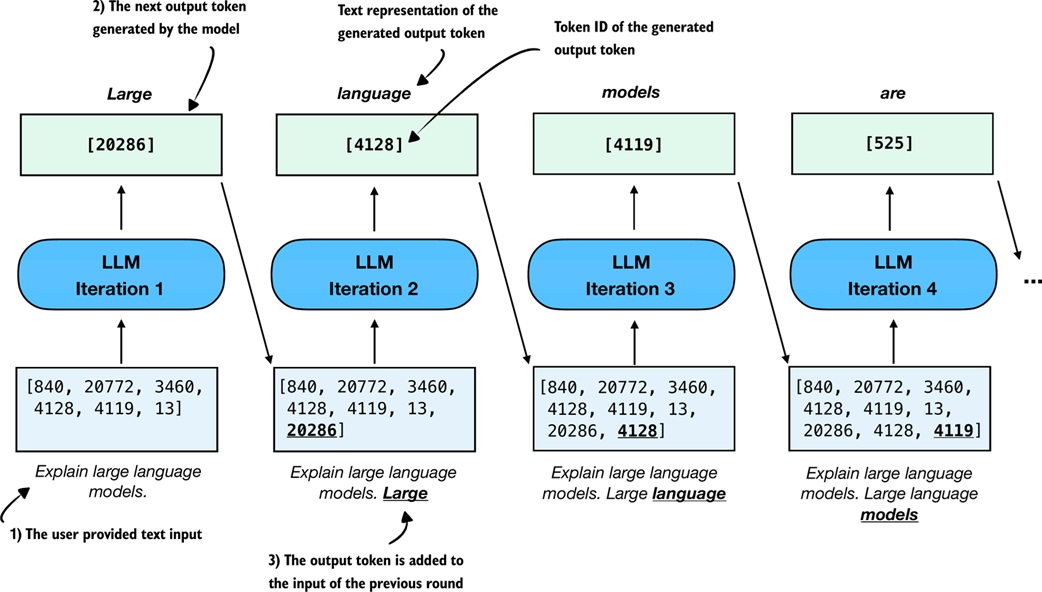
At each step:
1. feed the prompt plus generated tokens into the model
2. read the logits for the final position
3. choose the next token
4. append it to the sequence
5. repeat until stopping
This is the foundation that later reasoning techniques build on.
Core ideas¶
- Reasoning models are useful for tasks that need intermediate steps, such as math, coding, and logic puzzles.
- Reasoning can be more expensive because it often generates more tokens or makes multiple model calls.
- This notebook starts with a conventional pre-trained and instruction-capable LLM before adding reasoning methods later.
- Text must be encoded into token IDs before a model can process it.
- Token IDs must be decoded back into text after generation.
- Qwen3 0.6B is used because it is small enough for consumer hardware and has both base and reasoning variants.
- A model output is a logits tensor: scores for possible next tokens.
- For next-token generation, only the logits at the final input position matter.
- Greedy decoding chooses the token with the largest logit.
- Generation should stop at an end-of-sequence token when possible.
- Benchmarking tokens per second helps expose inference cost.
- KV caching speeds generation by reusing attention keys and values from previous tokens.
Walkthrough¶
Reasoning model context¶
The notebook opens by framing reasoning models.
A normal LLM can answer many everyday tasks:
A reasoning model is intended for tasks where the answer depends on several intermediate steps:
solve a math problem
debug code
follow a chain of logical implications
compare several possible plans
Reasoning is not free. If the model produces longer step-by-step outputs, it generates more tokens. Since each generated token requires model computation, longer outputs cost more.
Some reasoning workflows are even more expensive because they run the model multiple times, sample several candidate answers, use tools, or run a verifier.
Load the tokenizer¶
The model cannot read raw strings directly. The tokenizer converts text into integer token IDs.
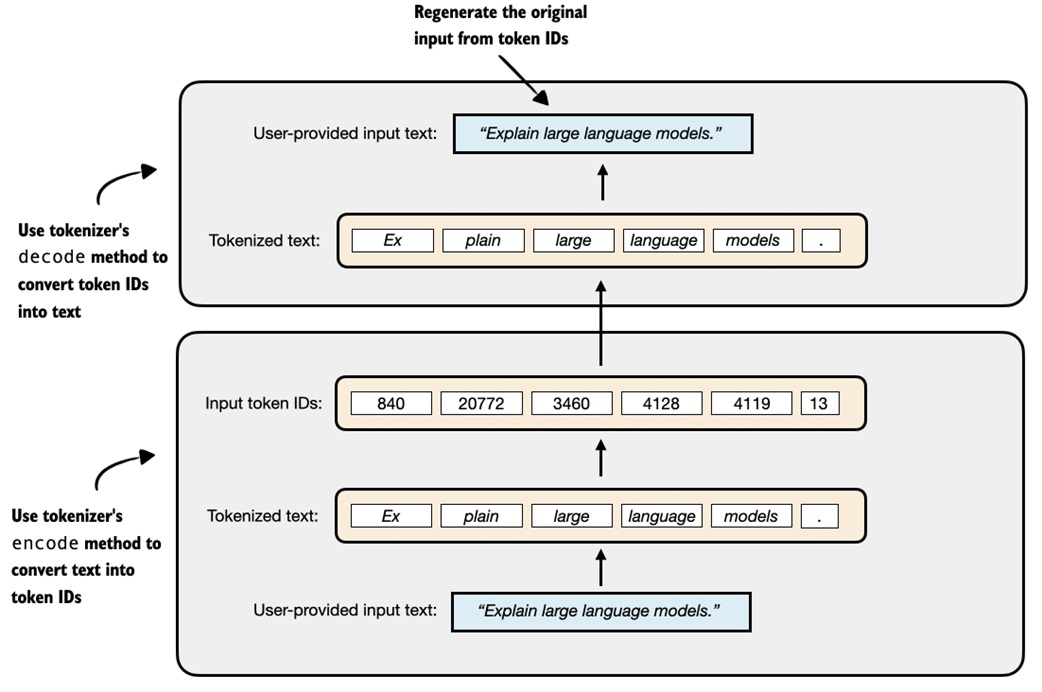
The notebook downloads and loads the tokenizer for the Qwen3 base model:
from pathlib import Path
from reasoning_from_scratch.qwen3 import Qwen3Tokenizer, download_qwen3_small
download_qwen3_small(kind="base", tokenizer_only=True, out_dir="qwen3")
tokenizer_file_path = Path("qwen3") / "tokenizer-base.json"
tokenizer = Qwen3Tokenizer(tokenizer_file_path=tokenizer_file_path)
Encoding:
Decoding:
Round-trip idea:
"Explain large language models."
-> [token_id_1, token_id_2, ...]
-> "Explain large language models."
The Qwen3 tokenizer has roughly 151,000 possible tokens.
Load the pre-trained model¶
The notebook uses Qwen3 0.6B.
Reasons:
- it is small enough to run locally
- it is still capable enough for demonstrations
- it has a base version and a reasoning variant for comparison
- the course package provides a pure PyTorch implementation
The device selection checks for available acceleration:
def get_device():
if torch.cuda.is_available():
return torch.device("cuda")
elif torch.backends.mps.is_available():
return torch.device("mps")
elif torch.xpu.is_available():
return torch.device("xpu")
else:
return torch.device("cpu")
Then the model weights are loaded:
from reasoning_from_scratch.qwen3 import Qwen3Model, QWEN_CONFIG_06_B
model_file = Path("qwen3") / "qwen3-0.6B-base.pth"
model = Qwen3Model(QWEN_CONFIG_06_B)
model.load_state_dict(torch.load(model_file))
model.to(device)
The model architecture can be treated as a black box for this notebook.
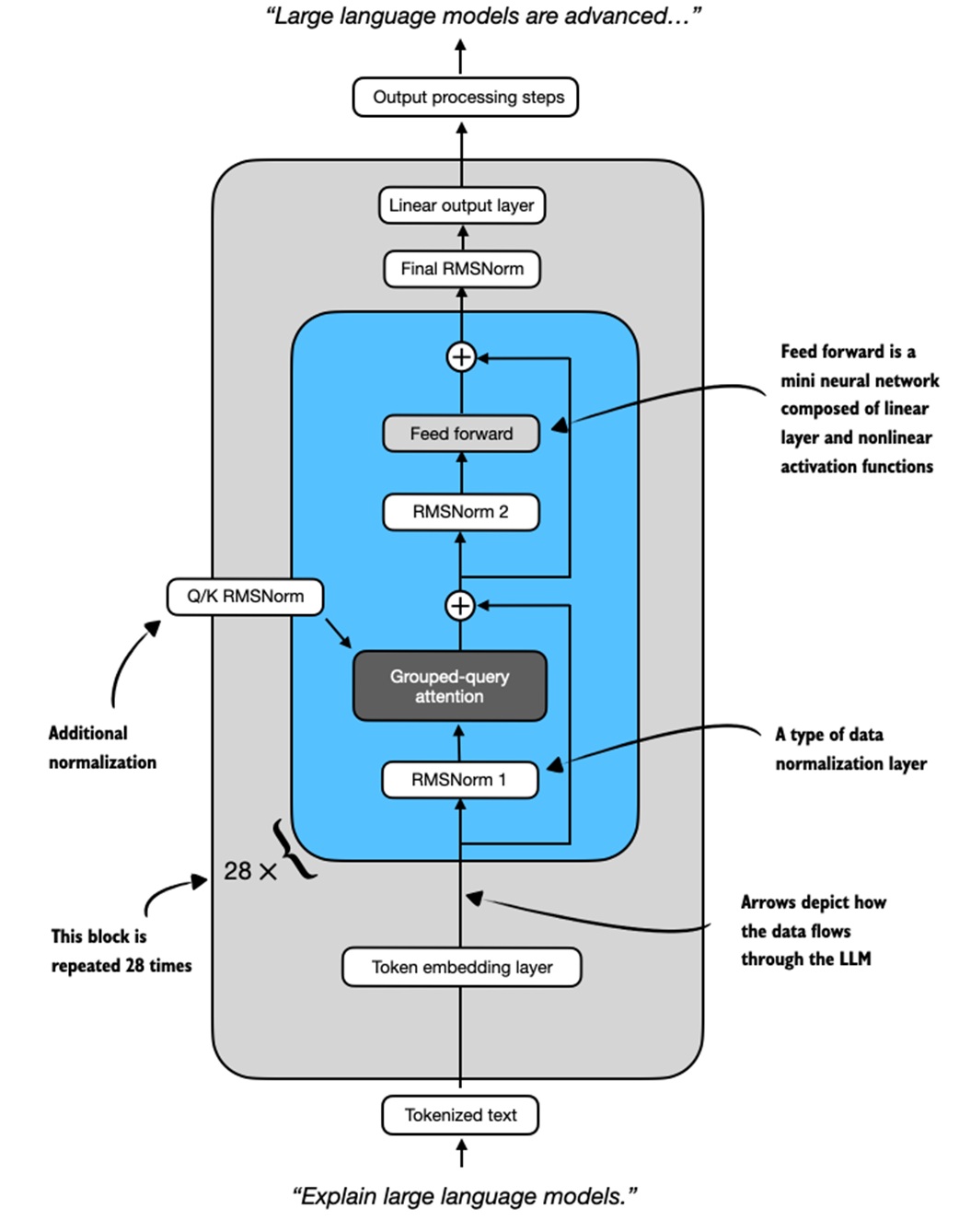
The important components are:
- token embedding layer
- stack of transformer blocks
- attention and feed-forward modules
- normalization layers
- output head that scores vocabulary tokens
One model call produces many rows of logits¶
Suppose the prompt tokenizes into six tokens.
When the model receives those six tokens, it returns one output row per input token:
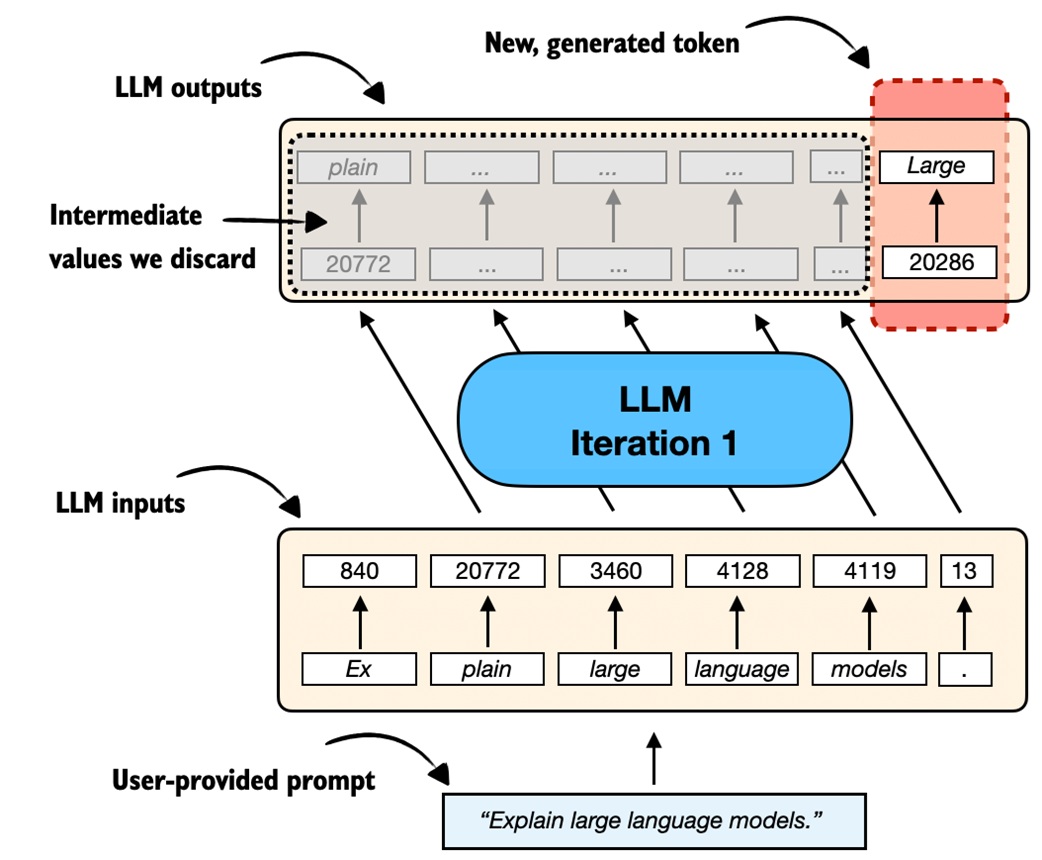
For Qwen3:
Meaning:
Each row contains logits: raw scores for every possible next token.
Use only the final row for generation¶
For the next generated token, we only need the last position:

output_tensor = model(input_tensor)
output_tensor = output_tensor.squeeze(0)
last_token_logits = output_tensor[-1].detach()
Why the last row?
The final input token is the position that has access to the full prompt so far. Its logits predict the next token after the whole current sequence.
Greedy decoding chooses the largest logit:
Then the token ID is decoded:
Minimal generation loop¶
One token is not enough. To generate a response, repeat the process.
@torch.inference_mode()
def generate_text_basic(model, token_ids, max_new_tokens, eos_token_id=None):
input_length = token_ids.shape[1]
model.eval()
for _ in range(max_new_tokens):
out = model(token_ids)[:, -1]
next_token = torch.argmax(out, dim=-1, keepdim=True)
if eos_token_id is not None and torch.all(next_token == eos_token_id):
break
token_ids = torch.cat([token_ids, next_token], dim=1)
return token_ids[:, input_length:]
Important details:
torch.inference_mode()disables gradient tracking for faster inference.model.eval()switches the model to evaluation behavior.max_new_tokensprevents unbounded generation.- the function returns only newly generated tokens, not the original prompt.
Using it:
prompt = "Explain large language models in a single sentence."
input_token_ids = torch.tensor(
tokenizer.encode(prompt),
device=device,
).unsqueeze(0)
output_token_ids = generate_text_basic(
model=model,
token_ids=input_token_ids,
max_new_tokens=100,
)
output_text = tokenizer.decode(output_token_ids.squeeze(0).tolist())
Stop at end-of-sequence¶
Without a stopping rule, the model may continue after a special delimiter such as:
The tokenizer exposes this ID:
Passing it into the generation function lets the loop stop once the model emits the end token:
output_token_ids = generate_text_basic(
model=model,
token_ids=input_token_ids,
max_new_tokens=100,
eos_token_id=tokenizer.eos_token_id,
)
Plain interpretation:
Measure generation speed¶
Inference cost matters because LLMs generate one token at a time.
The notebook defines a helper to report runtime:
def generate_stats(output_token_ids, tokenizer, start_time, end_time):
total_time = end_time - start_time
print(f"Time: {total_time:.2f} sec")
print(f"{int(output_token_ids.numel() / total_time)} tokens/sec")
output_text = tokenizer.decode(output_token_ids.squeeze(0).tolist())
print(output_text)
This gives a practical metric:
Reasoning workflows often produce more tokens or call the model multiple times, so this number helps estimate how expensive a method will be.
Why the basic loop is inefficient¶
The basic loop feeds the entire growing sequence back into the model every time:
step 1: prompt
step 2: prompt + token_1
step 3: prompt + token_1 + token_2
step 4: prompt + token_1 + token_2 + token_3
Most of that computation is repeated. Earlier tokens do not change.
KV caching¶
KV caching stores attention key and value tensors from previous tokens.
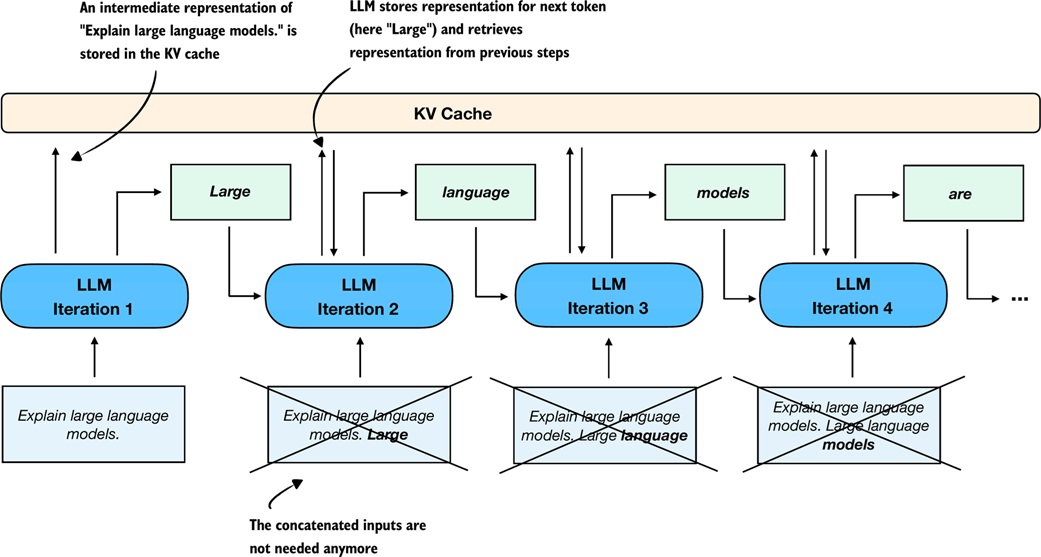
Without cache:
With cache:
process the full prompt once
then process only the newest generated token each step
reuse previous keys and values
The cached generation function follows the same logic but passes a cache into the model:
from reasoning_from_scratch.qwen3 import KVCache
@torch.inference_mode()
def generate_text_basic_cache(model, token_ids, max_new_tokens, eos_token_id=None):
input_length = token_ids.shape[1]
model.eval()
cache = KVCache(n_layers=model.cfg["n_layers"])
model.reset_kv_cache()
out = model(token_ids, cache=cache)[:, -1]
for _ in range(max_new_tokens):
next_token = torch.argmax(out, dim=-1, keepdim=True)
if eos_token_id is not None and torch.all(next_token == eos_token_id):
break
token_ids = torch.cat([token_ids, next_token], dim=1)
out = model(next_token, cache=cache)[:, -1]
return token_ids[:, input_length:]
The big change is here:
After the first full prompt pass, later iterations feed only the newest token.
torch.compile¶
The notebook also mentions torch.compile.
Plain idea:
It can reduce overhead, especially when the same computation pattern runs repeatedly. It is an engineering optimization, not a change to model behavior.
Common traps¶
Do not confuse token IDs with text
Token IDs are integer lookup values. The tokenizer is needed to convert between human-readable text and model-readable IDs.
Do not use all output rows for the next token
The model returns logits for every input position, but generation uses the final row because it predicts the next token after the whole current sequence.
Do not forget a stopping condition
Without max_new_tokens or an EOS token check, generation can continue far longer than intended.
Do not apply training habits during inference
Generation should use model.eval() and no-gradient inference mode. Gradients waste memory and compute here.
Do not assume greedy decoding is always best
Greedy decoding is simple and deterministic, but it can be repetitive or miss better continuations. Later sampling methods give more control.
Do not ignore inference speed
Reasoning methods often generate more tokens or make repeated calls. Tokens per second becomes part of the design trade-off.
Do not misunderstand KV caching
KV caching does not change the answer by itself. It avoids recomputing attention information for previous tokens.
Check yourself¶
What does the tokenizer do?
It encodes text into token IDs for the model and decodes generated token IDs back into text.
What shape does the model output have for a six-token prompt?
Conceptually it is [batch, 6, vocabulary_size]: one vocabulary-sized logits row for each input token position.
Why does generation use only the final logits row?
The final position has seen the whole current sequence and predicts the next token after it.
What does greedy decoding do?
It chooses the token with the largest logit at each generation step.
Why is max_new_tokens important?
It bounds the number of generated tokens so the loop cannot run indefinitely.
Why should generation stop at the EOS token?
EOS marks the model's learned end of a text segment or response. Continuing after it can produce off-topic or nonsensical text.
What problem does KV caching solve?
It avoids recomputing attention keys and values for previous tokens during each generation step.
Source anchors¶
notebooks/Module2/19a-Generating Text with a Pre-Trained LLM.ipynbstudy-guide/drafts/19a-generating-text-with-a-pre-trained-llm.md