Pretraining on Unlabeled Data¶
Why this matters¶
The previous lesson built a GPT-style architecture. This lesson makes it learn.
Pretraining is the stage where a language model learns from raw text without human-written labels. The labels are created automatically:
The model's job is always the same: predict the next token.
Mental model¶
Pretraining turns text into a self-supervised learning problem.
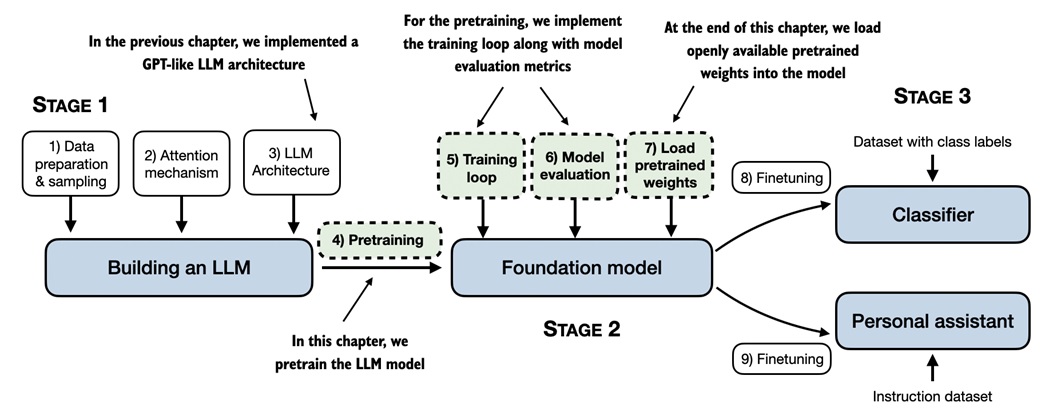
There is no separate annotation file. The text itself supplies the targets by shifting the sequence one token forward.
Training then follows the usual PyTorch pattern:
Core ideas¶
- Unlabeled text can train an LLM through next-token prediction.
- Model outputs are logits with shape
[batch, tokens, vocabulary_size]. - Targets are token IDs with shape
[batch, tokens]. - Cross-entropy loss measures how well the logits assign probability to the correct target IDs.
- Perplexity is the exponential of cross-entropy loss.
- Training and validation losses reveal whether the model is learning or overfitting.
- Small text datasets are useful for education but cause memorization quickly.
- Greedy decoding always picks the highest-scoring token.
- Temperature changes randomness during sampling.
- Top-k sampling restricts choices to the most likely tokens.
- Save both model and optimizer state if you want to resume training.
- Loading pretrained GPT-2 weights gives the model learned language ability immediately.
Walkthrough¶
From architecture to training¶
The notebook starts where the GPT architecture lesson ended:
Before training, generated text is incoherent because the model weights are random. To improve it, we need a numeric objective.
That objective is cross-entropy loss on next-token prediction.
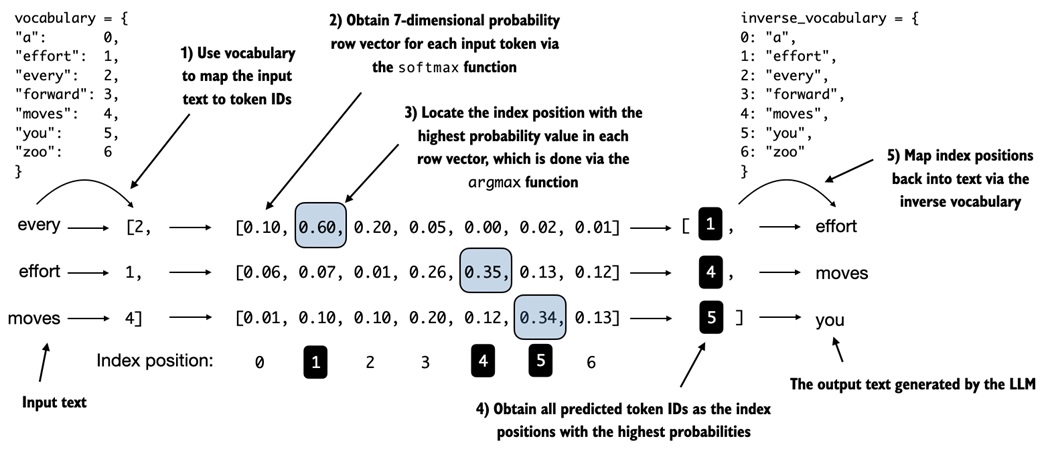
Text to token IDs and back¶
The notebook defines helper functions:
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
return torch.tensor(encoded).unsqueeze(0)
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0)
return tokenizer.decode(flat.tolist())
What this teaches:
unsqueeze(0)adds the batch dimension- generated token IDs must be decoded back into text
- these conversion helpers are used throughout training and sampling
Logits and targets¶
For a small batch:
inputs = torch.tensor([
[16833, 3626, 6100],
[40, 1107, 588],
])
targets = torch.tensor([
[3626, 6100, 345],
[588, 428, 11311],
])
The targets are the inputs shifted by one token.
When the model sees inputs, it returns:
For GPT-2 tokenization:
That means:
Cross-entropy loss¶
Training should increase the score assigned to the correct next token.
PyTorch's cross_entropy expects:
- logits flattened to
[batch * tokens, vocabulary_size] - targets flattened to
[batch * tokens]
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
You do not manually apply softmax before cross_entropy. PyTorch does the stable softmax/log-probability calculation internally.
Perplexity¶
Perplexity is:
Plain interpretation:
lower loss -> lower perplexity -> model is less uncertain
higher loss -> higher perplexity -> model is more uncertain
Perplexity can be thought of as an effective number of plausible choices the model is juggling at each step. It is not perfect, but it is a common language-model metric.
Training and validation data¶
The notebook trains on The Verdict, a short public-domain story.
This is intentionally tiny:
- useful for learning the mechanics
- fast enough to run locally
- too small for a serious LLM
- likely to cause memorization
The split is:
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
Then both subsets are wrapped with the text DataLoader from the earlier lesson:
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
)
The validation loader does not need shuffling.
Batch loss helpers¶
The batch-loss helper moves data to the same device as the model and computes cross-entropy.
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1),
target_batch.flatten(),
)
return loss
The loader-loss helper averages across batches:
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.0
num_batches = len(data_loader) if num_batches is None else num_batches
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i >= num_batches:
break
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
return total_loss / num_batches
num_batches lets you evaluate on only a few batches during training to save time.
Training loop¶
The training loop is standard PyTorch:
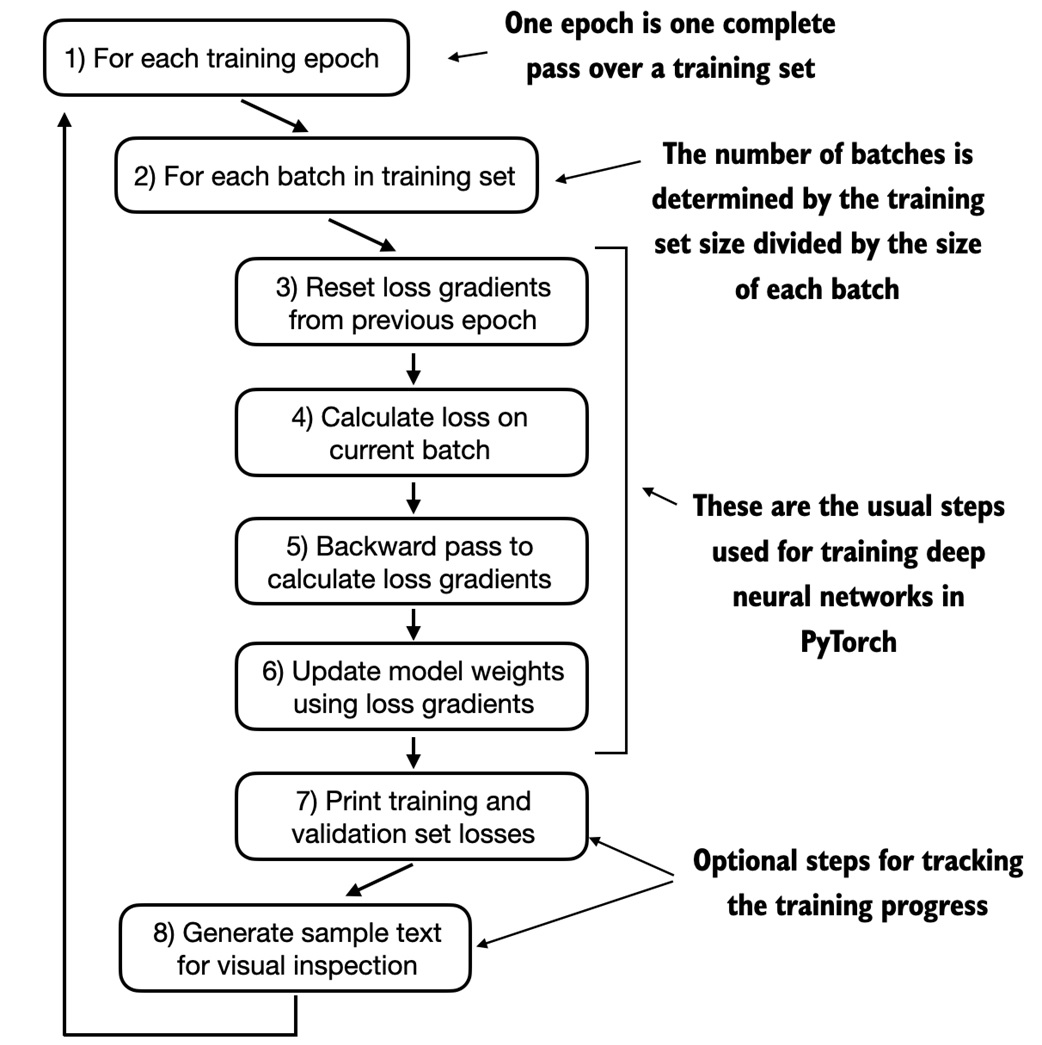
def train_model_simple(
model,
train_loader,
val_loader,
optimizer,
device,
num_epochs,
eval_freq,
eval_iter,
start_context,
tokenizer,
):
train_losses, val_losses, tokens_seen = [], [], []
global_step = -1
for epoch in range(num_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad()
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
optimizer.step()
global_step += 1
tokens_seen.append(input_batch.numel())
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(...)
train_losses.append(train_loss)
val_losses.append(val_loss)
generate_and_print_sample(model, tokenizer, device, start_context)
The core loop is:
zero gradients
compute loss
backpropagate
update weights
periodically evaluate
periodically sample text
AdamW¶
The notebook uses AdamW:
AdamW is a common optimizer for transformer models. It adapts update sizes per parameter and applies weight decay in a cleaner way than classic Adam with naive L2 regularization.
Overfitting on tiny text¶
The notebook trains for multiple epochs on a very small story.
The expected pattern:
training loss keeps falling
validation loss stalls or rises
generated text begins to memorize the story
This is not a failure of the code. It is a property of using a large model on a tiny dataset.
In real pretraining, the model sees vastly more text and usually only a small number of passes over the data.
Greedy decoding¶
Greedy decoding always chooses the highest-scoring next token:
This is deterministic. If the model and prompt are the same, the output is the same.
Greedy decoding is useful for debugging but often too repetitive for creative generation.
Temperature sampling¶
Temperature changes the sharpness of the next-token distribution.
scaled_logits = logits / temperature
probs = torch.softmax(scaled_logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
Interpretation:
- temperature near 0: very conservative, close to greedy
- temperature 1: normal probability distribution
- temperature greater than 1: more random and diverse, but riskier
Top-k sampling¶
Top-k sampling keeps only the k highest-scoring tokens.
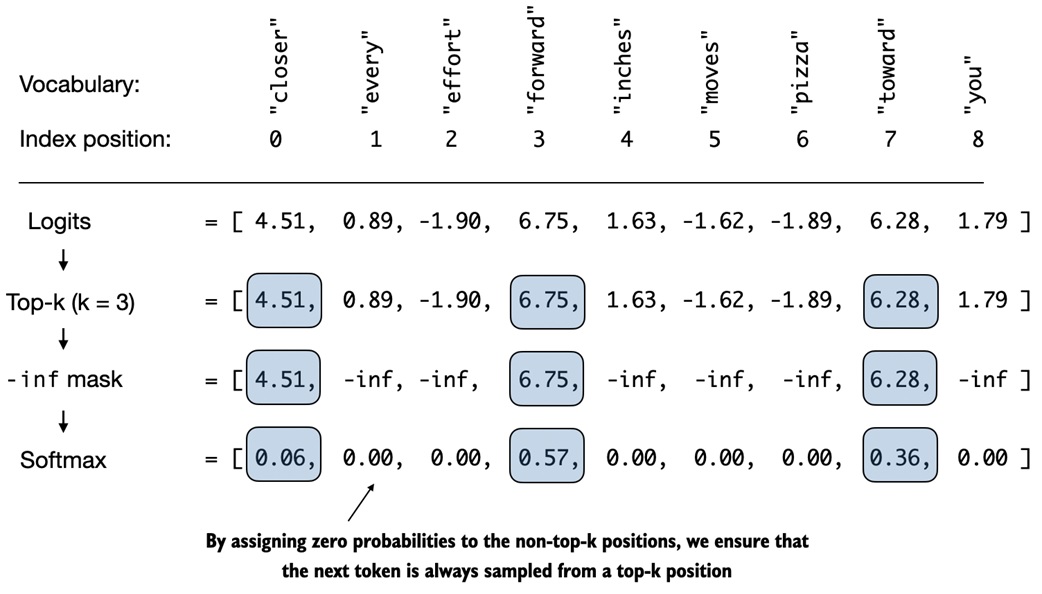
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(
logits < min_val,
torch.tensor(float("-inf")).to(logits.device),
logits,
)
Then softmax assigns zero probability to everything outside the top-k set.
Why it helps:
- temperature can add variety
- top-k prevents very unlikely tokens from being sampled
- together they are a simple way to balance diversity and coherence
Better generation function¶
The notebook combines top-k and temperature:
def generate(model, idx, max_new_tokens, context_size, temperature, top_k=None):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :]
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(
logits < min_val,
torch.tensor(float("-inf")).to(logits.device),
logits,
)
if temperature > 0.0:
logits = logits / temperature
probs = torch.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
else:
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
idx = torch.cat((idx, idx_next), dim=1)
return idx
This function is for inference, not training.
Saving model weights¶
Save learned model weights:
Load them into the same architecture:
Use model.eval() for inference because dropout should be disabled.
Saving optimizer state¶
If you want to resume training, save the optimizer too:
torch.save(
{
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
},
"model_and_optimizer.pth",
)
Restore both:
checkpoint = torch.load("model_and_optimizer.pth")
model = GPTModel(GPT_CONFIG_124M)
model.load_state_dict(checkpoint["model_state_dict"])
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005, weight_decay=0.1)
optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
model.train()
The optimizer state matters because AdamW tracks internal statistics. Resuming without it is not the same training run.
Loading pretrained GPT-2 weights¶
Training GPT-2 from scratch on a real corpus is expensive. The notebook shows how to load OpenAI's released GPT-2 weights into the course GPTModel implementation.
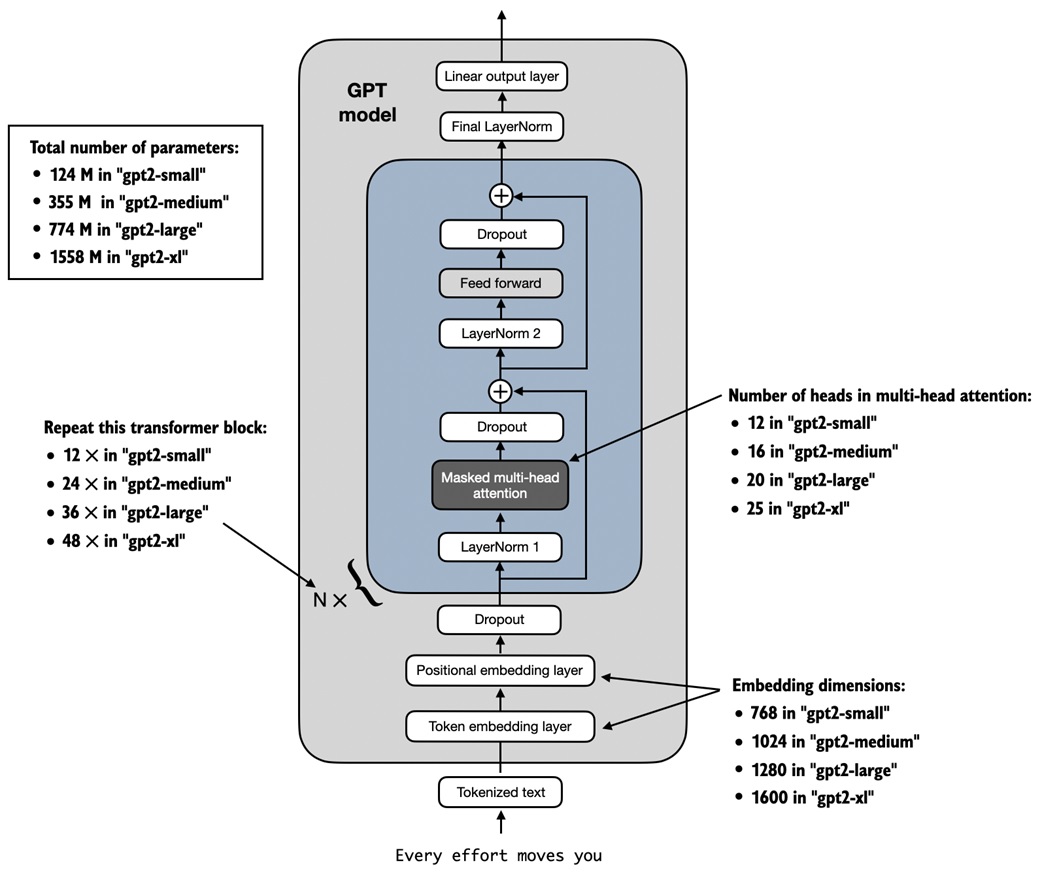
The loaded TensorFlow checkpoint contains:
- token embeddings
- position embeddings
- attention weights
- feed-forward weights
- layer-normalization parameters
- output-related parameters
The key detail is shape matching. The notebook uses an assign helper that refuses to copy weights if source and destination shapes differ.
Loading pretrained weights also requires matching architectural details:
- original GPT-2 context length: 1024
- query/key/value bias enabled for compatibility
- matching embedding dimension, layers, and attention heads for the chosen model size
Once loaded correctly, the model can generate coherent text without local pretraining.
Common traps¶
Unlabeled means there are no targets.
In language-model pretraining, targets are created by shifting the text by one token.
Apply softmax before cross_entropy.
PyTorch's cross_entropy expects raw logits and applies the stable log-softmax internally.
Low training loss means the model generalizes.
On tiny datasets, low training loss often means memorization. Check validation loss.
Perplexity is a separate training objective.
It is derived from cross-entropy loss. Training still minimizes cross entropy.
Temperature improves model knowledge.
Temperature only changes sampling behavior. It does not make the underlying model more accurate.
Top-k always makes output better.
Top-k reduces unlikely choices, but poor k and temperature settings can still produce weak text.
Saving only the model is enough to resume training exactly.
To continue training smoothly, also save and restore optimizer state.
Pretrained weights can load into any similar-looking model.
The architecture and tensor shapes must match precisely.
Check yourself¶
How are labels created for unlabeled text pretraining?
The target sequence is the input sequence shifted one token to the right.
What shape do GPT logits have?
[batch, tokens, vocabulary_size], because each token position gets a score for every vocabulary token.
Why flatten logits and targets before cross entropy?
PyTorch needs one row of logits per prediction and one target ID per prediction.
What does perplexity measure?
It is the exponential of cross-entropy loss and gives an interpretable sense of model uncertainty.
Why compare training and validation loss?
The comparison shows whether the model is learning general patterns or memorizing the training data.
What does temperature control during generation?
It controls how sharp or random the sampling distribution is.
What does top-k sampling do?
It restricts sampling to the k highest-scoring tokens and masks the rest.
Why load pretrained GPT-2 weights?
They provide language knowledge learned from large-scale pretraining, avoiding the cost of training from scratch.
Source anchors¶
This lesson rewrites the main ideas from 16-Pretraining on Unlabeled Data.ipynb:
- text/token helper functions
- cross-entropy loss for next-token prediction
- perplexity
- training and validation dataloaders for
The Verdict - batch and loader loss utilities
- simple GPT pretraining loop
- AdamW optimization
- loss curves and overfitting on tiny data
- greedy decoding, temperature sampling, and top-k sampling
- saving model and optimizer checkpoints
- loading OpenAI GPT-2 pretrained weights